
——不要把一整个zip文件或者答辩PPT上传到GitHub
当你不小心删除了某个工程的重要文件或者全部文件,你是否想象过后悔药的存在?当你与其他人一起开发/维护某一工程项目(甚至仅仅是完成本科课程作业)时你们是否在为了分工和进度争吵不断?当你来到GitHub时你是否完全无法使用除了CLONE之外的一切功能?Git将成为你最好的版本管理工具,而本文将较为粗浅的介绍这一工具的特性与使用方法。
本页内容概览
1.Git发展史与Git的安装配置
1.1 什么是版本控制
在一个工程的开发过程中,无论是硬件设计还是代码的编写通常会经过多次的修订和编撰,在此过程中我们可以将某些时间节点或者功能类别下“工程当时的状态”作为一个特殊的标志,也就是所谓的“版本”。不同于狭义线性的版本结构,我们通常认为版本有两种分类方式:
- 基于时间序列的,顺次产生的工程差异,例如IOS14.1与IOS14.4的区别
- 基于功能差分的,纵向区分功能类别的差异,例如windows10与windows11,二者虽然存在某种逻辑上的更新流程,但是显然这是windows两个不同的分支:他们某种意义上是并行发行且维护的
版本控制的本质其实就是对工程文件的管理,当然我们可以手动的去管理这些文件,仿佛旧时代的文献库保管员和检索人员一样,不过在拥有现代技术的今天,显然版本控制软件VCS(Version Control Software)是更加明智且高效的选择。那么不妨让我们首先了解一下版本控制软件VCS的几种类别:
1.1.1 本地版本控制
所谓本地版本控制,大多数设计人员和工程师在初学时就“生而知之”的能够使用:我们可以手动的建立不同的文件夹存放不同版本的工程文件,然后对不同文件夹中的文件做出保留、压缩、删除等等基本的文件操作。但是显然这种管理方式容错率极低,误删文件后基本只能够通过祈祷硬盘数据恢复工程师的神通广大来追回数据损失。基于以上想法和痛点,古早的开发者们研发了RCS工具用于本地版本管理,它的工作拓扑图如下所示:
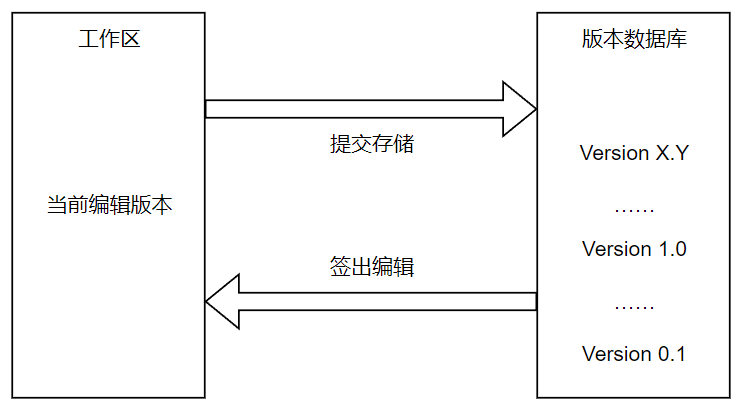
从这里开始,各位读者可以了解一些基本的版本控制范式和术语。首先,我们将我们正在编辑的文件和已经“存档”的过往版本文件分开存储:正在编辑的文件存放的区域称为工作区(Workspace),过往版本工程文件存放区域称为仓库(Repository);其次,我们将从仓库中取出某个版本到工作区供工程人员编辑的行为称之为签出(Checkout),反之将工作区中代码作为一个版本存放到仓库之中的行为称之为提交(Commit)。当然,假设我们不加管理筛查的一股脑地存放各种版本文件,那么版本控制的效果就微乎其微了,我们从中没有办法看到版本之间迭代或者变更的关系,因此在进行提交时,我们通常会同时提交注释性质的信息用于标记小版本做出的改变,这也就是日志(Log),日志往往包含提交时间和提交信息两部分。(在多人写作的版本控制信息中还包括提交者的身份信息,但是在本地版本控制中这往往是不必要的)
1.1.2 集中式版本控制
对于一些独行侠和全栈工程师来说,这样的版本控制工具其实已经能够完成大多数任务了,但是显然现代工程组织方式和工程规模决定了大多数的工程项目是不可能单人或者说单终端开发完成的。于是在这种思考方式下,将各个开发者的版本控制工具通过网络进行连接就是必要的了。下图表现了集中式版本控制工具的拓扑,这之中最著名的版本管理工具就是SVN。
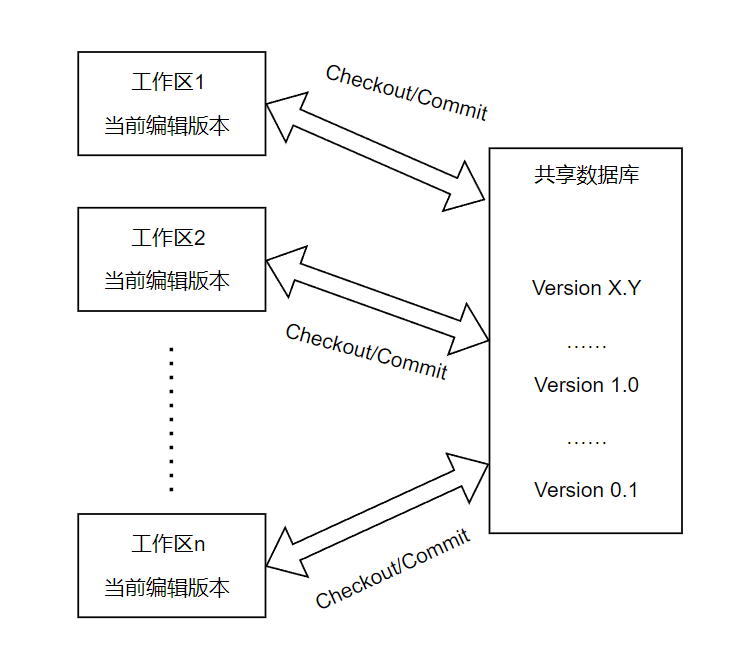
如图所示,集中式版本控制本质上就是将本地版本控制的仓库推送到云端的服务器进行管理,称为共享仓库(Shared Repositoty),这样每个开发者都能够在本地维护自己的工作区,而后与云端服务器进行通讯完成签出和提交的工作。但是这种方式有一个非常严重的问题:数据安全无法保证。众所周知,将多块硬盘联合组成存储池的RAID技术中(除了RAID0完完全全是为了扩容)的主要目的之一就是数据的安全备份。而集中式版本控制的硬伤就在于一旦中央服务器宕机,那么除了各个开发人员正在处理的快照(snapshot),整个工程所有的文件将会全部丢失。
1.1.3 分布式版本控制
基于版本控制的基本思想和改进集中式版本控制无法保证数据安全和服务器风险缺点的想法,我们开发出了分布式版本控制系统(Distributed Version Control System),也就是Git使用的版本控制模式。分布式版本控制系统除了Git之外还有Mercurial,Bazaar和Dracs等等。分布式版本控制系统拓扑如下所示:

马克思主义告诉我们,事物的发展通常是螺旋式上升的,在上图的拓扑结构中,显然在单节点中我们能够看到本地版本控制的影子,似乎就是将多个本地版本控制进行了机械的拼接。事实上,分布式版本控制的原理就是在本地版本控制的基础上加入了仓库和仓库之间的数据交流,也就是推送(Push)和拉取(Pull),进而完成了仓库与仓库之间的数据同步。这样以来,每个节点(开发者)手上都会留存有最后一次同步其他远程仓库时保存的副本。
不过考虑到现代互联网的网络结构,显然维持这样一个“区块链”式的版本控制网络是不经济且不效率的。所以在以上所有的节点中,我们选出一类特殊节点,这些特殊节点并不会保存在开发者手中的终端上,会保存在所有的开发者全部能够通过网络访问的服务器上,这种服务器并不具有“工作区”,只具有“仓库”的属性,换言之,相当于某种程度上的集中式版本控制网络的核心服务器:所有的开发者在Commit完成后将手中的版本Push到服务器,而新的版本开发可以从Pull服务器代码然后Checkout到本地工作区开始。
1.2 Git发展简史
众所周知,世界上最大的开源项目同时也是世界上最伟大的操作系统Linux的内核(Kernel)拥有广大的开发人员,在Kernel的早期开发过程中,具体而言是1991-2002年,内核代码的更改通常以补丁文件和压缩包的方式在开发人员中间传递。在2002时,Linux Kernel开始使用分布式版本控制系统进行管理,这个工具的名字叫做BitKeeper。
2005年时,Kernel开发的社区和开发BitKeeper的商业公司之间似乎爆发了一些小矛盾,于是BitKeeper取消了Kernel开源社区的免费授权(没人搞破解版??怕被告??),于是以Linus Torvalds为首的开发者们自己开发了一套分布式版本控制工具,也就是众所周知的Git。Git的开发者们指定的开发目标如下:
- 快速轻量级的工具
- 简单易上手的设计模式和工作流程
- 支持非线性工程开发结构(或许上千个并行的分支共同构建)
- 完全的分布式控制,不存在逻辑上的中心节点
- 能够抗住大型工程的开发
1.3 Git安装与基本配置
首先到Git官网下载页面下载对应你操作系统的Git版本,使用Windows系统的读者如果可以直接点击链接下载2.40.0 x64版本git,的如果读者使用的是Linux某个发行版例如Ubuntu或者CentOS那么读者可以直接使用系统嵌入的包管理器例如apt或者yum安装git,这里以Windows系统的Git安装举例。下载后以管理员权限运行EXE,如果没有额外要求,一直NEXT就可以,最后如果能够在右键菜单中找到”Git GUI Here”和“Git Bash Here”,代表Git安装成功。打开命令行输入git,如果有如下输出则证明git已经自动添加到系统环境变量,如果没有则需要用户手动添加环境变量。安装流程截图如下:
现在我们已经在操作系统上安装好了Git,然而每个人的开发环境不尽相同,作为个性化配置和对Git配置体系的了解,需要首先使用config命令配置参数。注意,这些参数会随着Git版本升级变化,重装Git也会变换,用户不必担心自己的配置参数不能持久化,这些参数可以随时进行配置。下面我们首先讨论存放Git配置文件的三种不同路径:
- [path]/etc/gitconfig path代表Git在操作系统中的安装路径,这一部分存放的git config是整个操作系统中使用此Git的所有成员和所有项目的git,可以通过 git config –system 进行读写配置。由于这部分配置将会影响到整个系统上的Git,所以需要管理员权限。
- ~/.gitconfig ~代表当前用户目录,例如windows下的用户abc就是C:/Users/abc。这部分配置存储的是计算机上使用Git的某一个用户的私人配置,可以通过 git config –global 进行读写配置,通常在这部分内容中存放git用户的身份信息。
- [project]/.git/config project代表具体工程项目的文件夹,也就是前文提到的workspace所在的目录,也成为工作目录。这部分Git配置仅仅与本工程项目有关,可以通过 git config –local 进行强制指定。
#要展示三个不同部分或者全部的git配置,使用如下命令
git config --local --list
git config --global --list
git config --system --list
git config --list
#如果想要查看global区段的配置项目"abc.xyz"那么可以使用:
git config --global abc.xyz
#如果想要将该字段改写为"test message"那么可以使用:
git config --global abc.xyz "test message"Git是一个分布式版本控制软件,用于多人协作开发,因此在Git代码仓库中提交时标定提交者身份是必要且重要的。在Git中标定身份(并非验证身份,验证身份常用密码或者干脆SSH密钥)主要使用”用户名“和”用户邮箱“两个字段,这两个字段不配置无法连接远程仓库。这两个字段在global区进行配置:
#假设用户名为 "Fenice Liu" 用户邮箱为 feniceliu@fenice.website
git config --global user.name "Fenice Liu"
git config --global user.email feniceliu@fenice.website2.Git的工作流程分析
Git的基础工作流程中包括三个逻辑部分:首先要区分的就是仓库和工作区,仓库又分为远程仓库和本地仓库。那么就分为远程仓库,本地仓库,工作区三个部分,这时候可能有读者会问”暂存区去哪里了“,事实上暂存区也储存在.git目录之下。在这三者之间整个工作流程中常用的命令有六类。Git工作流程的整体框架分析图如下所示:
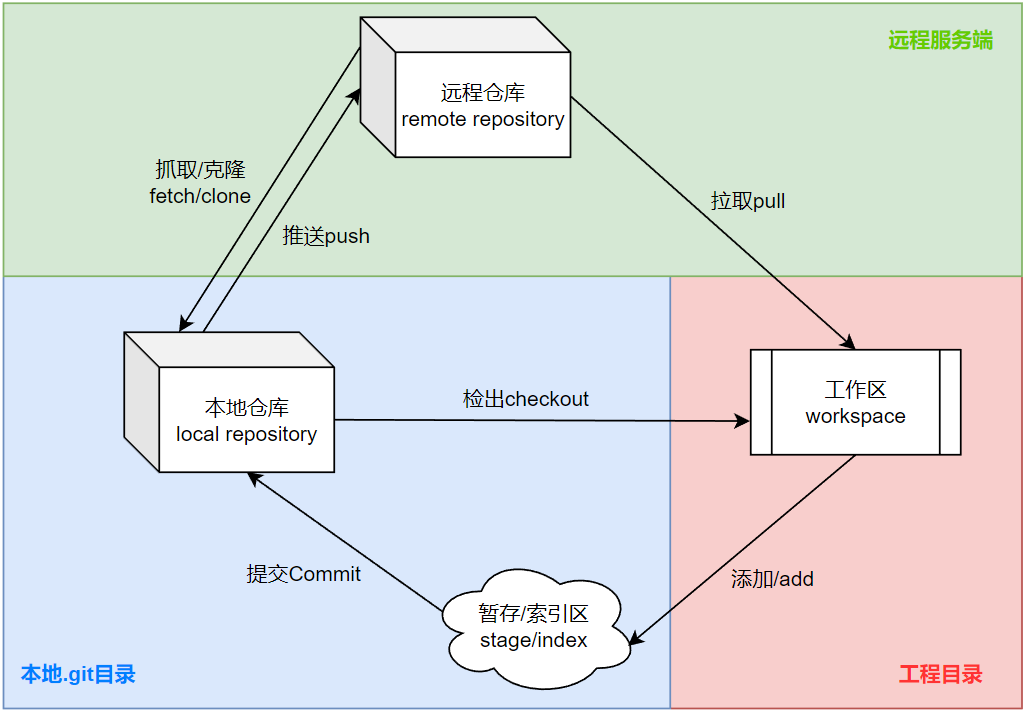
首先我们来讨论图中出现的四部分空间:本地仓库,远程仓库,暂存区,工作区和三部分文件划分:工程目录,本地.git目录,远程服务端:
- 工作区,同样也是工程目录。顾名思义,这就是我们主要存放工程文件的区域,在这个区域中工程设计人员可以尽情的修改工程项目文件的内容。如同上文中提到的,工作区的内容除了自己编写之外还可以通过下载远程仓库内容(pull)或者签出本地仓库内容(checkout)来实现。
- 远程仓库,一般指部署在云端或者所有开发人员都能通过网络访问的Git服务器。这里主要是作为开发人员之间同步项目进度的”公共水池“和云端备份使用,更新远程仓库的手段只有一个,只能够通过本地仓库中已经提交的代码推送(push)到云端。
- 本地.git目录,这个目录一般隐藏在工程根目录之下,用于存放本地仓库和暂存区。这里需要说明的是,我们并非不能够直接将整个工作区保留归档到本地仓库,但是在实际的使用过程中通常一些临时文件,编译中间文件等等我们没有必要也没有需要将其保存到代码文件中,那么这部分内容就需要同真正的工程文件区分开来。
- 暂存区,又称索引区,一般处于.git/index中,称为暂存区比较形象,只有在暂存区中的文件才能够提交到仓库,如果有一份文件仅仅处于工作区中没有存放到暂存区中,它不在git的跟踪管理范围内。但是其工作原理的本质表明了这并不是一个存储空间而是一个索引文件。当我们将工作区中的文件提交到仓库时,Git会按照索引index记录的文件列表从工作区中获取文件。
- 本地仓库,存储在.git目录中,可以通过本地工作区提交(commit)或者克隆云端仓库改变,而本地仓库中的内容同样可以签出(checkout)到工作区或者推送(push)到远程的其他仓库。
其次,我们要明确一点,git之所以能够灵活清凉的管理众多工程文件并不是Git真的拷贝跟踪了每个工程文件,也就是说在Git仓库管理记录中你无法找到完整的工程文件数据。那么Git是如何知道我们对工程文件做出了改动的呢,本质上Git使用了工程文件的哈希(Hash)校验值,这样就可以通过比对两份文件的校验值而判断文件是否一致。
最后,在基本的Git工作流程中我们只用到了6(7)个基本的git命令:也就是:克隆(clone)/抓取(fetch)、推送(push)、拉取(pull)、添加(add)、提交(commit)、签出(checkout),在文章的下一个章节我们将会详细的介绍阐明它们的用法。
3.Git仓库基本管理命令
3.1 创建/克隆一个Git仓库
在开始一切的Git命令使用之前,首先我们必须拥有一个Git仓库,Git仓库可以通过开发者自行创建或者克隆(clone)一个已经存在的远程Git仓库。我们会将Git仓库存放在一个目录之中,这个目录就是我们未来工程文件所在的目录。需要注意的是,无论是创建还是克隆一个Git仓库,都需要这个目录未被纳入其他的Git仓库管理范围内,并且开发者如果选择克隆一个远程仓库,那么这个用于存放Git仓库的目录需要是一个空目录。如下是将本目录(执行命令行时所在的目录)创建Git仓库的指令:
git init需要注意,一般MacOS和Linux打开终端位置位于用户目录,而Windows在普通模式下终端打开于用户目录也就是C:/Users/<YourUserName>,但是以管理员身份打开时打开于C:/windows/system32。这时候我们可以用上文提到的在目标目录下右键菜单打开“Git Bash Here”的方法打开终端于本目录。当然,在命令行中我们还有其他的手段,假设我们想要建立仓库的位置是C:/ProjectDirectory,那么可以这样做:
#第一种方法是先移动到该目录再初始化仓库
cd C:/ProjectDirectory
git init
#第二种方法是直接指定仓库位置,语法为 git init [创建Git仓库的目录位置]
git init C:/ProjectDirectory除了自己建立Git仓库之外,我们很多时候可能都需要修改其他开发者的工程版本或者干脆使用别人造的轮子,这个时候我们就需要用到克隆(clone)命令,注意,clone的目标目录必须是空目录,用法如下:
#语法 git clone <Remote Git Repository URL> [Custom Directory Name]
#必选参数是远程仓库的URL,例如著名整活项目HeLang的URL是https://github.com/kifuan/helang.git
git clone https://github.com/kifuan/helang.git
#这句代码就会在当前目录下新建一个helang文件夹然后把整个项目的内容复制进去
#如果你不想使用自动生成的目录名,你可以指定:
git clone https://github.com/kifuan/helang.git CyberDingZhen
#这句代码就会在当前目录下新建一个名为CyberDingZhen的文件夹并且将整个项目copy进去
#URL不一定使用http协议或者https协议,还可以使用ssh协议,不过这样需要SSH密钥。例如:
git clone ssh://git@github.com:kifuan/helang.git在上一小节中我们曾经提到Git的基础工作流程中除了Push/Pull/Commit之外还存在一个特殊的动作叫做克隆(clone),这个动作和普通的复制粘贴不一样的地方在于,clone命令不仅仅将代码签出到工作区(显然这是checkout的功能),还会将整个Git仓库中存放的版本信息与Git仓库本身一并拷贝下来。这个功能呢大大增强了多节点Git管理系统的鲁棒性。想象一下,假设我们有一台中心服务器,一台镜像服务器,镜像服务器实时同步中心节点仓库中存放的内容。当中心服务器宕机,镜像服务器便可以马上承担起中心节点的角色,并且中心服务器的恢复仅仅需要git clone一下镜像服务器即可。这意味着在单节点故障率不高的情况下,设置多个节点相互同步将会使工程文件近乎绝对安全。
3.2 管理不同状态的文件
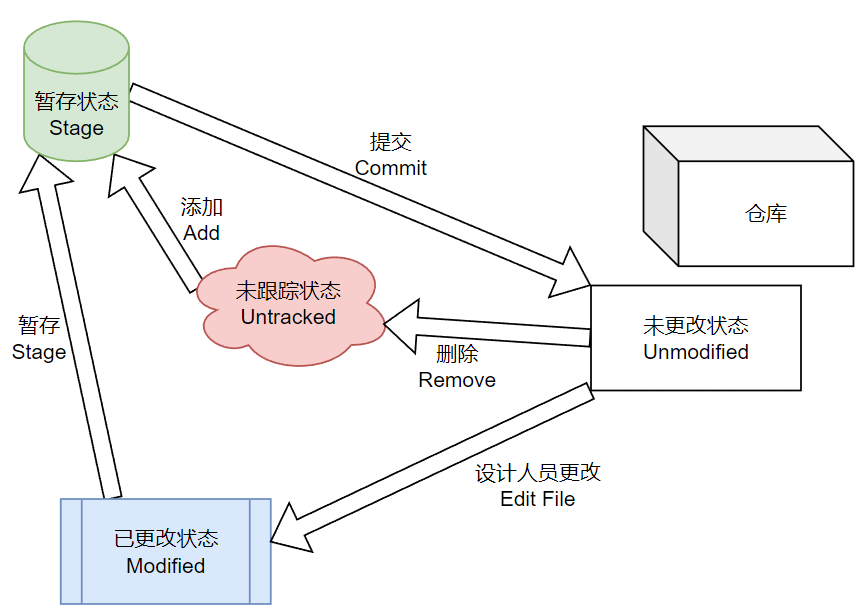
上图是Git文件管理系统中对四种文件状态的区分:未跟踪(Untracked)、未更改(Unmodified)、已更改(Modified)、已暂存(Staged)。这四种状态可以解释如下:
- Untracked未跟踪:版本控制的本质其实就是追踪一个个文件的改变过程,任何的工程都是由一个一个文件构成的,未跟踪的文件事实上就不在工程管理的范围内,尽管他们很可能在工程目录下。
- Unmodified未更改:未更改的工程文件事实上就是“仓库中存储的文件”。当然,前文中提到过,Git使用Hash校验值判断文件是否改动,以减小版本记录仓库的体积,这里的未更改本质上就是说文件的Hash校验值与Git仓库中记录的校验值一致。
- Modified已更改:这个状态代表用户改动了位于工作区(Workspace)中的文件,使得此文件与Git仓库中记录的最新版本的文件发生了差异。显然这个文件已经被追踪,但是我们仍要明确的一点就是这个文件的改动Git尚不知晓(未进行暂存)。
- Staged已暂存:这个状态是除了Push/Pull/Clone之外唯一能够改变Git仓库中版本信息的状态。所有的文件无论是新添加的还是修改的(当然不包括删除的,删除的只要直接取消掉跟踪状态就好了)都需要先进入暂存模式,而后通过提交(Commit)操作同步到仓库中。
为了避免读者通过抽象的描述想象接下来涉及到的各种Git版本管理的基础命令,我们在虚拟机中建立一个仓库来作为试验,仓库建立如下所示:
#新建仓库命名为TestRepo
git init TestRepo
cd ./TestRepo
#新建文件
touch LICENSE
touch test.c
#添加到暂存区
git add test.c
git add LICENSE
#首次提交并且通过-m参数指定提交信息
git commit -m 'Initialize Project'
#commit执行结果如下:
#[master (root-commit) 6ba9eee] Initialize Project
# 2 files changed, 0 insertions(+), 0 deletions(-)
# create mode 100644 LICENSE
# create mode 100644 test.c3.2.1 查看当前文件状态
已知Git中文件有四种状态(歪:回有四种写法……),那么我们显然不可能靠记忆记住每个文件的状态,那样也失去了版本控制的意义,于是我们可以通过git status命令常看当前状态:
git status
#status查询结果如下:
#On branch master
#nothing to commit, working tree clean我们先不要管branch是什么[注:Git的默认分支叫做master,但是在2020年时GitHub和GitLab同时将默认分支改名为main,但是这并不影响Git本身],这是下一小节的内容。可以看到在我们什么都没改变的状况下,Git检测到工作区WorkSpace中的文件Hash校验值和Git中的校验值相符,并且Git也没有检测到未跟踪untracked的文件出现。下面将演示当我们新建一个文件时会发生什么:
#添加文件README.md
touch README.md
git status
#status查询结果如下:
#On branch master
#Untracked files:
# (use "git add <file>..." to include in what will be committed)
# README.md
#
#nothing added to commit but untracked files present (use "git add" to track)3.2.2 添加追踪文件与暂存修改文件
虽然将未追踪的文件纳入管理范围和将修改后的文件重新暂存在逻辑上不相同,但是在具体的操作步骤上都是将工作区中Hash校验值与Git仓库中不符(没有追踪也是一种不符)的文件标记到暂存区。故而,这两个操作用到的命令都是git add。书接上文,命令语法如下所示:
#将刚才新加的文件README.md添加track
git add README.md
git status
#status 查询结果如下:
#On branch master
#Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# new file: README.md
#修改LICENSE
echo "GPL v3.0" > LICENSE
git status
#status 查询结果如下:
#On branch master
#Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# new file: README.md
#
#Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git restore <file>..." to discard changes in working directory)
# modified: LICENSE
#将修改后的LICENSE暂存
git add LICENSE
git status
#status 查询结果如下:
#On branch master
#Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# modified: LICENSE
# new file: README.md显然,通过status查询输出我们发现,当我们新建文件和修改文件后,相关文件都会被Git检测到不在暂存区中,通过add命令存入暂存区后,这些文件就会被标记为”Changes to be committed“变成待提交的文件变更记录了。这里有三点需要明确:
- 假设某文件在git init之前就存在,那么在git init之后这些文件不会被自动添加到Git仓库中,而是统统被标记为未追踪untracked文件进行处理。
- 当git add的对象是一个目录,这个目录以及其内部文件,内部目录都会被递归的加入到暂存区中。但是我们始终要强调:空目录不会被记录到Git中去,Git仓库存储的是文件的变化,目录只不过是用来表征文件结构的一种辅助数据,而并不是可以被独立记录的数据。
- 我们需要明确:修改文件本身也是将文件从暂存区中取出的动作,假设我们在commit之前修改了新track文件README.md的内容,那么这个文件的状态又将变回“未暂存”,我们需要重新add。
3.2.3 提交变更与跳过暂存步骤
经过前面的步骤,新加入的文件和变更的文件都已经进入到暂存区之中,下一步就是将他们存入到Git仓库之中,通过commit提交命令实现:
#直接commit是不会有提交时的日志信息的,需要通过-m选项添加记录:
git commit -m "Add README and modified LICENSE"
#commit输出
#[master 26e0fd1] Add README and modified LICENSE
# 2 files changed, 0 insertions(+), 0 deletions(-)
# create mode 100644 README.md假设我们没有通过-m选项写入提交记录,那么git会在命令行中给我们打开一个编辑器(editor)让我们书写提交日志(考虑到有人的提交日志很长,或者格式上较为复杂),这些编辑器可以设置,不过默认的编辑器设置为vim,第一行为空行,其余为注释不会提交。如果用户在编辑器中没有书写任何提交信息那么本次提交将会作废。设置编辑器语句为:
#例如设置编辑器为vim
git config --global core.editor vim
#加入想在commit时同时提交具体的文件差异信息,可以加入-v选项:
git commit -v
git commit -v -m "Your Commit Message"从逻辑上来说,细致入微的编辑好暂存区后进行提交当然可以从版本管理层面做好每一次快照(Snapshot)的编辑和记录工作,但是显然很多时候这种编辑暂存区的步骤从技术上来说还是过于繁琐了,于是Git为我们这些懒人提供了可以跳过暂存区的手段。我们可以加入选项-a就能够让所有被修改过的文件加入到暂存区中(新增文件还是要手动add),不需要我们使用git add进行手动添加,例如:
git commit -a -m "Your Commit Message"3.2.4 删除、移动、忽略文件
在上一部分中,我们使用了-a选项来一键提交,跳过手动add的步骤,但是我们很可能会有某一类文件不想提交到Git仓库中去,例如编译产生的中间文件、嵌入式项目中用于参考的数据手册和例程代码、能够使用包管理工具下载的工具包源码等等。我们可以通过.gitignore文件控制哪些文件默认不受Git的管辖。编辑使用该文件如下所示:
#如果没有该文件可以选择新建这个文件
touch .gitignore
#查看文件内容
cat .gitignore
#改写文件内容(使用vim)
vim .gitignore
#注意.gitignore文件本身也要commit- .gitignore文件作用于其所在目录的所有子项目,并且递归生效。故而管理整个项目的ignore文件应当放置在工程根目录;当然其他的子目录也可以有自己的ignore文件
- .gitignore文件一般来说作为项目文件的一部分也要commit,但是无论是否commit,它都生效
- .gitignore文件遵循通配符表达式,针对不同的语言和工程结构,GitHub有ignore文件的例程项目,对于该文件的编写,下面给出一个Git官方的例子
#忽略所有.a文件
*.a
#符号!可以用来反选,例如我们要保留lib.a
!lib.a
#只忽略当前目录下的TODO,而不是所有目录下的TODO
/TODO
#忽略整个build目录
build/
#忽略doc目录下所有的txt
doc/*.txt
#忽略doc目录和它子目录下所有的pdf
doc/**/*.pdf- 规则A:空行或者#开头的行,其内容不被计算在内
- 规则B:开头加入斜杠(/)可以避免递归Ignore生效,结尾加入(/)可以限定生效对象为一个目录
- 规则C:可以使用叹号(!)来反选
- 通配规则A:星号(*)可以用于指代0个及以上的任意字符,双星号(**)代表递归通配
- 通配规则B:问号(?)可以用于指代1个任意字符
- 通配规则C:中括号([…])代表1个处于枚举范围内的字符,例如[acx]代表a或者c或者x;而[5-9]代表任意单个大小在5到9之间的阿拉伯数字。
#下面来看一个忽略test.c编译产生test.o的列子
touch .gitignore
echo "*.o" >> .gitignore
#将printf Hello World的程序写入test.c
echo "#include<stdio.h>
void main(){
printf(\"Hello World\");
}" >> test.c
#编译生成.o文件
gcc test.c -o test.o
git status
#看status结果,发现没有计入test.o
#On branch master
#Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git restore <file>..." to discard changes in working directory)
# modified: test.c
#
#Untracked files:
# (use "git add <file>..." to include in what will be committed)
# .gitignore
#
#no changes added to commit (use "git add" and/or "git commit -a")
#将所有Changes存入暂存区
git add .
#提交
git commit -m "Test .gitignore"当我们删除一个文件时,Git会出现workspace和暂存区之间的差异,例如我们现在删除掉README.md,这会导致暂存区中仍然留存着README.md的信息,但是实际的工作区中这个文件已经消失了,这个时候就需要通过git rm命令来完成:
rm README.md
git status
#status查询结果如下:
#On branch master
#Changes not staged for commit:
# (use "git add/rm <file>..." to update what will be committed)
# (use "git restore <file>..." to discard changes in working directory)
# deleted: README.md
#
#no changes added to commit (use "git add" and/or "git commit -a")
#在Git暂存区中删除
git rm README.md
git status
#status查询结果如下:
#On branch master
#Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# deleted: README.md
#提交Changes
git commit -m "Delete README"- 使用-r选项可以实现递归删除
- 使用–cached选项可以只删除暂存区记录但是不实际删除文件,如果不加,那么二者同时删除。当我们执行了–cached删除而没有删除实际的文件,文件就会重新变成未跟踪untracked状态
- 在git rm中使用通配符(*)要添加反斜杠变成转义字符(\*)
对于文件的操作:新建,删除,更改内容,更改位置或者文件名,我们只剩下最后一项更改文件位置或者文件名。看似是两种不同的操作,但是从磁盘存储和文件系统的角度来讲只要不跨磁盘移动这二者就是相同的实际操作,接触过Linux的同学都知道,这二者是统一使用mv命令实现的。所以在Git中移动文件或者重命名也要使用git mv,如下所示:
#重命名为HelloWorld.c
git mv test.c HelloWorld.c
git status
#status查询结果:
#On branch master
#Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# renamed: test.c -> HelloWorld.c
#当然这个操作可以拆成如下三步等效实现:
mv test.c HelloWorld.c
git rm test.c
git add HelloWorld.c
#提交
git commit -m "Rename Code"3.2.5 更详细和更简短的查看Changes
在上文的实践中,我们发现git status是非常有用的命令,但是它给出的信息和我们实际需要的信息量完全不对等,我们不需要如此臃肿的status输出,故而Git也给我们准备了更加简洁的输出:
#输入以下任意一种形式的status参数,既可以得到简短的输出
git status -s
git status --short
#以下是举例输出,格式为"标识符 文件名"
M README
# M代表Modified,更改过的文件
R makefile
# R代表Renamed,重命名过的文件
A lib/git.rb
# A代表Added,新建后加入Git仓库的文件
?? LICENSE.txt
# ??代表新建但是并未加入Git仓库的文件
D CMakeList.txt
# D(D前方有空格)代表Deleted,只在文件中删除了,Git中未暂存
D CMakeList.txt
# D (D后方有空格)代表服务器和本地都删掉了有时我们在详细的工程版本控制过程中依靠status输出的数据还是不能够做出精准的判断,如果我们不仅仅想知道什么文件被修改了,我们还想知道什么文件做了什么修改,那我们就需要输出修改文件的细节。这时候我们就会用到git diff命令:
#查看当前工作区和暂存区之间的区别:
git diff
#查看当前暂存区和上一次commit之间的区别(两种写法):
git diff --cached
git diff --staged
#事实上查看文件细节差别不只有命令行工具,命令行工具中也不只有如此简陋的工具
#使用如下命令查看更加细节丰富的差异信息
git difftool
#使用更多的diff信息工具可以通过如下命令查询
git difftool --help3.3 查看Git版本历史[项目经理问责神器]
在我们callback一些远古工程或者和其他人协作时,我们常常需要了解代码是如何编写的,工程是如何一步一步被构建的,这时候只能看到现有差异的git status显然是不够的。我们可以使用git log命令查看过去工程经历过的提交(commit):
#在我们的TestRepo中执行log
git log
#log输出如下
commit 2a8a67ef70a8193c049200d82e160a87971f15c5 (HEAD -> master)
Author: Fenice Liu <feniceliu@fenice.website>
Date: Wed Apr 12 03:06:40 2023 +0800
Rename Code
commit 0658006ec7e95647610cc3f75147eb166f637e3a
Author: Fenice Liu <feniceliu@fenice.website>
Date: Wed Apr 12 02:37:00 2023 +0800
Delete README
commit a633bb9db439e00cd99fea3be7d2e392d3fe94a4
Author: Fenice Liu <feniceliu@fenice.website>
Date: Wed Apr 12 02:31:43 2023 +0800
Test .gitignore
commit 7f9867fc110a4f6a4b8cb26171e343c43bccc58e
Author: Fenice Liu <feniceliu@fenice.website>
Date: Wed Apr 12 02:14:49 2023 +0800
Add README and modified LICENSE
commit a07262ffc020d5ce4cc96b9892b15f1910c61403
Author: Fenice Liu <feniceliu@fenice.website>
Date: Wed Apr 12 02:12:58 2023 +0800
Initialize Project如上我们可以看到五次提交消息,第一行的commit记录了本次提交的SHA-1校验值,第二行的Author记录了提交者的用户名和账户邮箱,第三行记录了GMT标准时间下的提交时间戳,最后是我们commit时自定义的提交信息。在默认的没有任何参数时,这个命令会显示所有的提交记录,假设说我们的工程有着较为复杂的提交历史,那么喷薄而出的日志信息绝对会将开发人员淹没,但是同时无参数的命令又没有任何其他的详细信息。事实上log命令拥有众多且繁杂的参数组合,我们在这里只展示少数常用参数如下:
| 命令行选项 | 命令行参数作用描述 |
| -p –patch | 输出各个提交之间的补丁(patch)信息 |
| –stat | 输出每个提交的文件更改统计数据(statistics) |
| –shortstat | 对比上一选项,只输出 变更(changed) 插入(insertions) 删除(deletions) |
| –name-only | 在输出提交信息后只输出更改(modified)相关的文件名 |
| –name-status | 对比上一选项,除了更改(modified)还输出添加(added)和删除(deleted)文件名 |
| –abbrev-commit | 输出commit的Hash校验码时只输出前几位而不是整个40位 |
| –relative-date | 输出相对时间,例如今天是4月12日,那么4月10日的提交显示为2 days ago |
| –date | 使用–date=来指定输出日期的具体格式 |
| –graph | 在命令行中使用ASCII字符来图形化的显示各个提交(commit)和分支(branch)的关系 |
| –pretty | 使用–pretty=来美化log信息输出 |
| –oneline | 相当于 –pretty=oneline –abbrev-commit |
3.3.1 git-log命令的常用参数
#参数 -p 或者 --patch 展示commit信息中具体的diff信息
#以下命令不展示所有patch,只展示最后两次的patch
git log --patch -2
#当然无参数的log也可以这样用例如 git log -2 显示最后两次的基本commit信息
#输出如下
#commit 2a8a67ef70a8193c049200d82e160a87971f15c5 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code
#
#diff --git a/test.c b/HelloWorld.c
#similarity index 100%
#rename from test.c
#rename to HelloWorld.c
#
#commit 0658006ec7e95647610cc3f75147eb166f637e3a
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 02:37:00 2023 +0800
#
# Delete README
#
#diff --git a/README.md b/README.md
#deleted file mode 100644
#index e69de29..0000000#参数 --stat可以展示每次提交的变更文件数量以及多少行具体的代码被更改
#--stat参数相比于--patch会展示和Changs状态更加相关的信息
git log --stat -2
#输出如下
#commit 2a8a67ef70a8193c049200d82e160a87971f15c5 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code
#
# test.c => HelloWorld.c | 0
# 1 file changed, 0 insertions(+), 0 deletions(-)
#
#commit 0658006ec7e95647610cc3f75147eb166f637e3a
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 02:37:00 2023 +0800
#
# Delete README
#
# README.md | 0
# 1 file changed, 0 insertions(+), 0 deletions(-)| 小写 | 小写输出内容 | 大写 | 大写输出内容 |
| %a | 星期几的缩写例如 周六为Sat | %A | 星期几的全拼例如 周六为Saturday |
| %b | 月份的缩写,例如四月为Apri | %B | 月份的全拼例如 十月为October |
| %c | 格式化输出为 “%x %X” | %H | 24小时制的第几个小时 |
| %d | 一个月中的第几天 | %I | 12小时制的第几个小时 |
| %j | 一年中的第几天 | %M | 分钟 |
| %m | 月份数字,例如04、12 | %S | 秒钟 |
| %p | 上午还是下午: AM/PM | %U | 一年之中的第几个周 |
| %w | 星期几(0~6:Sun~Sat) | %W | 一年之中的第几个周 |
| %x | 格式化输出短日期 [月份/日期/短年份] | %X | 格式化输出短时间 [小时:分钟:秒钟] |
| %y | 年份后两位,例如2020年输出为20 | %Y | 年份,输出整个四位的公元纪年 |
| %z | 时区,东八区为+0800 | %Z | 无此输出格式 |
#例如我们输出为 Year:xxxx <MothName>-<Date> [<Weekday>] hh:mm:ss"
git log --date=format:"Year:%Y %B-%d [%A] %X" -2
#输出内容,注意log中的日期格式
#commit 2a8a67ef70a8193c049200d82e160a87971f15c5 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Year:2023 April-12 [Wednesday] 03:06:40
#
# Rename Code
#
#commit 0658006ec7e95647610cc3f75147eb166f637e3a
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Year:2023 April-12 [Wednesday] 02:37:00
#
# Delete README3.3.2 git-log命令美化参数和输出控制
个人认为在整个git log命令的参数中,–pretty参数是对于开发人员最有价值和最为复杂的。这个参数并不对于log输出的内容做出更改,–pretty参数仅仅是优化log内容的展示形式。这个参数可以设置为一些Git自带的输出格式,例如oneline模式就会将每个提交信息精简为一行:
git log --pretty=oneline
#输出如下所示:
#2a8a67ef70a8193c049200d82e160a87971f15c5 (HEAD -> master) Rename Code
#0658006ec7e95647610cc3f75147eb166f637e3a Delete README
#a633bb9db439e00cd99fea3be7d2e392d3fe94a4 Test .gitignore
#7f9867fc110a4f6a4b8cb26171e343c43bccc58e Add README and modified LICENSE
#a07262ffc020d5ce4cc96b9892b15f1910c61403 Initialize Project除了oneline之外,–pretty自带的输出模式还有例如short、full、fuller等简单且易用的模式。但是当我们查阅日志时我们通常希望日志按照自定义的方式输出,这就要用到format模式,format模式的格式化字符串中的模式字符如下所示:
| 格式化字符 | 对应输出内容 |
| %H | 提交Commit对应的Hash校验值 |
| %h | 缩写后的提交Hash校验值 |
| %T | 工作树(Work Tree)对应的Hash校验值 |
| %t | 缩写后的工作树Hash校验值 |
| %P | 该次提交的Parent的Hash校验值 |
| %p | 缩写后的Parent的Hash校验值 |
| %an | Author Name:文件的创建者的用户名 |
| %ae | Author Email:文件的创建者的电子邮箱 |
| %ad | Author Date:文件的创建日期[日期的格式可以通过–date选项控制] |
| %ar | Authro Date Relative:文件创建时间的相对日期 |
| %cn | Committer Name:提交者用户名 |
| %ce | Committer Email:提交者电子邮箱 |
| %cd | Committer Date:提交的具体日期 |
| %cr | Commiter Date Relative:提交的相对日期 |
| %s | 主题[提交信息] |
#以下是一个--pretty的例子:
git log --pretty=format:"HASH:%h - Committer:%cn[commit:%cr] - Message:%s"
#log的格式化输出如下:
#HASH:2a8a67e - Committer:Fenice Liu[commit:10 hours ago] - Message:Rename Code
#HASH:0658006 - Committer:Fenice Liu[commit:11 hours ago] - Message:Delete README
#HASH:a633bb9 - Committer:Fenice Liu[commit:11 hours ago] - Message:Test .gitignore
#HASH:7f9867f - Committer:Fenice Liu[commit:11 hours ago] - Message:Add README and modified LICENSE
#HASH:a07262f - Committer:Fenice Liu[commit:11 hours ago] - Message:Initialize Project在之前的叙述中,我们能够通过”-条目数量“控制git log的输出数目为最后若干条提交的详细信息。有时我们不仅仅需要这样过滤出相关信息,我们很多时候需要输出所有commit中满足某一条件的一个子集的条目信息,我们在时间过滤上可以通过”–since –after –until –before“等参数控制:
#输出两周前到现在所有的信息
git log --since=2.weeks
#输出两周之前以及更早的信息
git log --until=2.weeks
#还可以给定一个日期
git log --since="2022-04-10"
#或者是一个相对日期
git log --since="2 years 4 month 1 day 3 minutes ago"除了从时间上过滤之外,还可以通过–author对文件的创建者做出过滤,可以通过–committer对文件的提交者做出过滤,可以通过–grep对提交信息做出过滤。最重要的一个参数是”-S”,如果将Git类比为著名游戏Minecraft,那么这个选项就是“镐子”,这个选项可以过滤出代码变更中含有的内容:
#假设我们要过滤出提交信息中对函数void setup(int code)有关的提交
git log -S "void setup(int code)需要注意的是,上述所有的过滤条件都可以混合共同使用。但是!!git默认的过滤方式是逻辑或,也就是假如我们对于author和committer同时做出要求,那么满足条件之一就可以显示出来。如果我们要满足所有的条件才输出,也就是逻辑与,我们需要加入–all-match选项。以上过滤方法总结如下:
| 命令选项 | log命令过滤条件 |
| -<n> | 输出所有commit之中最后n条数据 |
| –since,–after | 输出在某一个日期或者相对时间之后的所有数据 |
| –until,–before | 输出在某一个日期或者相对时间之前的所有数据 |
| –author | 输出提交变更文件中具有特定创建者(author)的数据 |
| –committer | 输出提交变更文件中具有特定提交者(committer)的数据 |
| –grep | 输出commit message中含有特定字符串的数据 |
| -S | 输出提交变更代码中含有特定字符串的数据 |
| –all-match | 将过滤条件转变为逻辑与 |
| –no-merges | 不显示和分支合并(branch merge)相关的提交数据 |
3.4 如何优雅的回滚[Git牌后悔药]
版本控制最令人心动的功能也是最救命的功能就是可以在大的尺度上进行“撤销”操作。我们称这种撤销操作为“回滚”,通过对于Git工作流程的了解,我们发现,在若干个不同的步骤我们都有机会也都有需要进行这种可撤销的操作。首先就是当我们过早的进行了提交,例如我们忘记了添加某些文件或者我们错误的写入了提交信息。这时候我们当然想做完补充性的步骤然后一并写入上一次提交,这时候我们不必新建一次commit而是可以通过参数 –amend补全:
git log -1
#log输出如下所示:
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code
#新建文件后使用--amend追加到上次提交
touch test.c
git add test.c
git commit -m "Rename Code and Newfile" --amend
#重新查看log
git log -1
#log输出结果如下:
#commit 4b0105c646479e821d9037cda62efa3a82939ca4 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code and Newfile注意amend操作在逻辑上是我们“修补”了上次不完整的不正确的提交,但是实际上Git是取消了上次的提交,转而用这次的提交覆盖替代了上次的提交。所以一旦你的改变已经Push到了远程仓库,那么amend操作是仅仅能够影响本地Git仓库的,无法直接覆盖远程仓库。除了在提交阶段出错需要回滚之外,我们还非常有可能错误的暂存某个文件,例如错误的更改,或者把本不应该在此次提交中变更的文件暂存……这个时候我们需要取消掉文件的暂存状态。关于暂存区的问题我们不妨看一个例子:
git log -2
#commit 4b0105c646479e821d9037cda62efa3a82939ca4 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code and Newfile
#
#commit 0658006ec7e95647610cc3f75147eb166f637e3a
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 02:37:00 2023 +0800
#
# Delete README我们通过log的输出信息可以看到最后一次提交信息比之前一次的提交信息多了(HEAD -> master),那么这是什么意思呢?HEAD是一个指针,总是指向某次commit并标定暂存区的状态,我们下次提交的commit将会自动成为HEAD指针的子节点,代表着二者是版本迭代关系。因此,我们只要重设HEAD就可以撤回对暂存区的修改,说白了暂存区本身不存储文件,只是起索引作用:
touch new.c
git add new.c
git status
#status输出信息:
#On branch master
#Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# new file: new.c
#撤销new.c的HEAD
git reset HEAD new.c
git status
#status输出信息:
#On branch master
#Untracked files:
# (use "git add <file>..." to include in what will be committed)
# new.c
#
#nothing added to commit but untracked files present (use "git add" to track)
#删除掉该文件,恢复原样
rm new.c需要注意的是git reset是一个非常危险非常危险的命令,尤其是很多应用场景中都带有–hard选项。在上方的例子中,只不过是因为reset只改动了暂存区没有改动真实的文件才显得这个命令没有那么危险。既然谈论到改动真实文件,那就不得不提到Git也提供了对于真实文件的回滚功能,也就是如何取消对一个已追踪并提交的文件的修改。这一功能本质上是从Git仓库取出数据存放到工作区中,所以使用chekcout:
#首先改动 test.c
echo "void f(){}" >> test.c
git status
#通过git status查询可以看到标记为modified的文件:
#On branch master
#Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git restore <file>..." to discard changes in working directory)
# modified: test.c
#
#no changes added to commit (use "git add" and/or "git commit -a")
#取消test.c文件的更改,恢复为Git仓库中的样子
git checkout test.c
git status
#status查询结果如下,改变被撤回了:
#On branch master
#nothing to commit, working tree clean事实上,相比于reset命令,checkout命令也具有一定的危险性,因为这个命令会造成worksapce中任何没有提交的数据不可逆的丢失;这里需要注意的是,删除文件可以用checkout来恢复,但是移动文件的撤销需要通过上文中提到的git reset命令完成。
在上述功能中,很多撤销动作给人一种形似神又似的感觉,让人觉得完全没有必要划分如此多的命令,不会增加便利性的同时反而背离了git轻量易用的宗旨。在Git Version2.23.0中我们新加入了一个命令用于统一的进行撤回动作:git restore。使用方法极其简单,如下所示:
#如果想要从暂存区中撤销一个文件的改动:
git restore --staged <file>
#如果想要改变的是实际工作区中的文件:
git restore <file>相比于之前通过工作流程位置的不同区分撤回动作的方法,restore命令的切入点是需要撤销回滚数据的存储位置,这无非就两种,一种是工作目录,一种是暂存区,默认改动的是工作目录,暂存区需要加入限定选项–staged。
3.5 Git连接远程仓库进行多人协作
如果我们想要备份代码到云端或者与多人进行工程开发合作,我们就要有至少一个远程仓库并且能够在本地对远程仓库进行操作。在这一部分中我们暂不讨论搭建Git服务器的内容,我们只是着眼于如何使用已经存在的远程Git服务器和操作远程仓库。远程仓库本质上就是能够通过互联网访问的一个存放着与本地工程有关代码的远程Git数据库。事实上我们可以连接到若干个远程仓库,然后动态的管理每一个远程仓库,例如将他们作为只读仓库或者R/W仓库。
3.5.1 管理远程仓库
在远程仓库的管理之中,其实还是增删查改老四项,我们这里先讨论增删查的问题,也就是如何添加一个远程仓库,如何删除一个远程仓库,如何查看一个远程仓库的信息,这些操作统统都要通过git remote命令实现,首先来看如何添加一个Git远程仓库:
#语法: git remote add <远程仓库名称> <远程仓库URL>, 例如:
git remote add origin https://github.com/somebody/testrepo
git remote add another git@gitlab.com:somebody/newrepo.git
git remote add sshrepo ssh://git@git.dns.xx:18822/somebody/test.git在上方的命令中,远程仓库的名称默认为origin,但是其实可以根据开发人员的喜好任意命名,只要保证远程仓库的URL是正确的,并且开发者账户具有访问权限即可。可以看到上方的命令中URL既可以通过ssh/git协议连接也可以通过http/https协议连接,不过由于日益增加的安全需求,现在GitHub与GitLab大多要求开发者采用SSH密钥认证,这部分内容将在3.5.2小节中展示。如何删除和查看远程仓库如下:
#首先是如何重命名一个存在的仓库,例如将origin替换为public
git remote rename origin public
#其次是删除掉一个存在的仓库,例如删除public
git remote remove public
#查看已经存在的git远程仓库
git remote
#如果想要查看详细信息,可以加入-v参数
git remote -v
#查看某一个仓库,例如origin的详细信息:
git remote show origin3.5.2 以GitHub/GitLab为例配置SSH-Key
#首先,保证git config中的用户邮箱与Github/GitLab中的邮箱一致
#用户名无所谓,只是在Web端显示Contribute的时候才会显示
git config --global user.email <your_email>
git config --global user.name <custom_username>
#其次,生成ssh密钥,需要保证这里的邮箱与网页端填写的邮箱一致
ssh-keygen -t rsa -C "your_email"
#一路回车即可
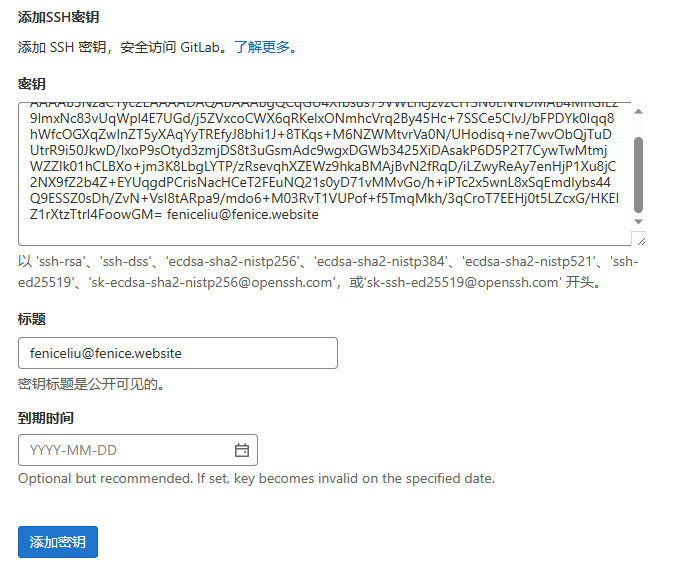
#打开用户目录下的隐藏目录.ssh,可以看到密钥,pub文件就是公钥
#记事本打开pub复制到网页端即可完成添加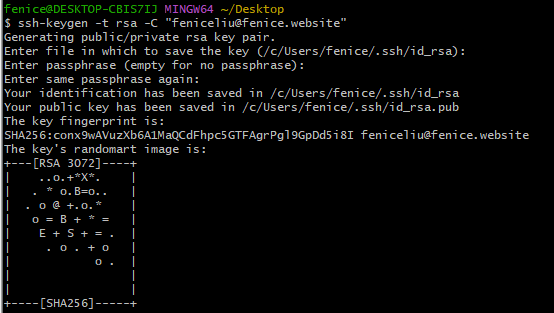

3.5.3 与远程仓库传递数据
针对于远程仓库的数据传递总共只有两种方向:从本地向远程的叫做推送(Push),从远程向本地仓库传递叫做拉取(Pull)或者抓取(Fetch)。很多读者这里可能已经开始疑惑了,抓取和拉取究竟有什么区别呢?事实上从远程获取数据明显可以分成两个步骤:首先是查看一下远程服务器上的仓库有什么改变,这个步骤就是抓取(Fetch);其次才是将我们选定的指定分支和指定提交同步到本地,也就是拉取(Pull)。这三个步骤的基础命令如下所示,其中Pull或许会牵扯到分支(branch)管理的问题,这个将在下一章中讨论:
#抓取远程仓库origin的信息:
git fetch origin
#推送当前本地仓库内容到远程origin的master分支:
git push origin master3.6 Git标签[特别的爱给特别的版本]
当我们的工程有了一定的开发经历之后,就会拥有很多个commit和对应的snapshot,这里面势必有一些版本是非常特殊的,例如完成某个功能的开发,消除了某一类BUG等等。众多的版本控制工具都有将特殊节点标记的能力,Git也有这个功能,Git将特殊的commit称之为标签(Tag)。
#git tag命令可以查看当前工程拥有的tag,以字典序排出
git tag
#如果是想要筛查某些特定版本,可以用-l --list + 通配表达式,例如列出1.8.x的tag
git tag --list "1.8.*"在Git中,支持这样两类标签(Tag):轻量级标签(Lightweight Tag)和注释标签(Annotated Tag)。前者非常简单,就像是一个不会改变的分支一样,单纯就是标记某个特殊commit的点,可以理解为一个单纯的标记没有其他的任何功能。注释标签就稍微复杂一些:它事实上在Git数据库中表征为一个信息相当完备的数据条目,拥有校验值、创建者信息、创建日期、随Tag附带的信息。它甚至可以使用GPG进行签名和校验,从逻辑意义上已经很接近“发行版(release)”这个概念了。下面来看如何创建Tag:
#创建轻量级标签(Lightweight Tag)只需要一个标签名即可将当前commit标记为Tag,例如
git tag v1.0-beta.build.264
#创建注释标签(Annotated Tag)就需要使用选项-a,同样的Tag Message通过-m给出,例如
git tag -a v1.0-release -m "Basic functions are completed"
#以上标签都可以通过show + 标签名查看详细信息,例如
git show v1.0-release
#当然我们也可以将非当前commit创立为Tag,只需要使用该commit的Hash校验值即可
#假设git log --pretty=oneline 输出如下
#4682c3261057305bdd616e23b64b0857d832627b Add todo file
#166ae0c4d3f420721acbb115cc33848dfcc2121a Create write support
#例如要将Create Write support新建为一个Tag,既可以使用完备的Hash值例如:
git tag -a v1.0 166ae0c4d3f420721acbb115cc33848dfcc2121a -m "Create Write Support Tag"
#也可以仅仅使用该Tag的Hash值的一部分(也就是git输出的那个短Hash值):
git tag -a v1.0 166ae0c -m "Create Write Support Tag"Tag创建后,就如同普通的commit一样存在于Git数据库之中,在Tag管理中我们还涉及三个问题,首先就是删除已有的Tag,其次是将已有的Tag签出到工作区以便编写程序。最后呢,Git有一个特性就是不会将Tag推送到远程服务器(这是为了保护各个本地开发者自己的标签完备性不受别人影响),我们在git push时可以加入一些参数保证Tag被推送。Tag推送和删除的具体命令如下:
#假设远程仓库名称为origin,那么向远程推送tag的push命令为:
git push origin v1.0-release
#默认提交所有tag的语句为
git push origin --tags
#只提交较为正式的Annotated Tag而不提交Lightweight Tag
git push origin --follow-tags
#删除tag时需要使用选项 -d 并且指定tag的名称,例如
git tag -d v1.0-release
#删除远程服务器上的tag
git push origin :refs/tags/v1.0-release
#事实上上述命令生效的原理是向tag推送了一个null信息从而覆盖掉
#更为严谨的删除命令为
git push origin --delete v1.0-release我们有时需要将一整个Tag的具体代码签出到工作区,也许我们只是想观摩一下Tag的内容,也许我们是想做出一些对比,也许我们是想更改这个Tag代表的代码,我们可以checkout:
git checkout v1.0-release虽然这样目标Tag的内容确实会签出到工作区,但是整个HEAD信息会处于“Dead HEAD模式”,在这种模式下,我们仍可以做出变更并且提交,但是对应的commit不会属于任何一个分支,也就是说除了使用特定的Hash校验值我们没有任何方法可以定位到这个commit。解决办法为签出时指定一个分支:
git checkout -b version1.0 v1.0-release
#Git会为我们新建一个分支version1.0并且将v1.0-release这个tag签出到该分支3.7 Git Alias[自带的命令宏工具]
有时在git中我们常用到一些简单但是具有很大输入复杂度和难度的命令,这个时候我们仿照C语言中的宏定义,仿照Shell中的alias命令,Git也可以有自己的命令“缩写”或者说“替换”:
#语法 git config [可选--global --local --system] alias.<新命令的名字> "替换命令内容"
#下面是例子
git config alias.unstage "reset HEAD --"
git unstage fileA
#上述命令就会替换成 git reset HEAD -- fileA4.Git分支模型与冲突管理
4.1 Git中的分支(Branches)模型与工作流程
几乎所有的版本控制软件都会做一定的分支管理工作,何谓分支?其实就是从工程主线中copy出一个备份用于开发和调试,但是同时又不会搞乱工程主线。Git的分支功能一直被世界各地的开发者们盛赞为”Killer Feature”,这个功能决定了Git屹立在所有版本控制工具的顶峰并且开创了软件开发史上首个繁盛的非线性开发生态。如果要真正的了解Git的分支模型,我们也需要“回滚”一下来看看Git究竟是怎样工作的。
4.1.1 Git的存储方式与分支定义
#新建git仓库
git init
#新建三个文件:自述文件README、证书文件LICENSE、源代码test.c
touch README LICENSE test.c
#将文件添加到git仓库中
git add README LICENSE test.c
#提交
git commit -m "Initial Repo"在前文的叙述中,我们提到过Git并不直接存储文件本身,而是存储文件的Hash(SHA1)校验值。在这种存储模式中,我们又可以做出如下两类存储细分:
- 存储第一次Commit的文件内容,而后记录每次Commit相对于上次的改变(Differences)
- 存储每次Commit的具体内容,也就是记录每次的快照(Snapshot)版本
Git的存储方式是后者,当我们进行一次提交时,Git存储的信息事实上是一个指针,指向了我们在暂存区中提交的内容,这个指针包括如下几项内容:
- 提交者的身份信息:用户名与邮箱(Commiter’s Username & Email)
- 本次提交的日志信息(Commit Message)
- 提交的来源(Parent):代表了本次提交从何处改变而来;0个Parent代表着本次提交是初始化仓库的提交(Initial Commit),1个Parent代表着本次提交是由Parent变更得来,2个Parent代表着本次提交是两个不同的分支(Branch)的末次提交合并(Merge)得来。
- 本次提交的具体内容
显然,这样的数据格式非常像是我们在各种通讯协议,例如HTTP协议,中的数据划分方式也就是:除了具体内容之外带有一部分“头部信息”。这部分头部信息其实很好理解,下面我们来探讨一下“具体内容”是如何储存的。当我们发出commit命令时,Git会在每个子目录(subdirectory)下对所有的文件展开校验工作得出每个文件的SHA1校验和(checksum),每个文件得出的校验和和文件内容被整编成一个blob结构,工程的文件子目录结构被整编成一个tree结构,整个工程形成一个树状存储结构,这颗树的根节点就是Git仓库所在的根目录,而Commit指针指向这个根节点。上方代码构成的Commit结构示意图如下所示:

需要注意的是,我们举例的工程结构比较简单,没有二层子目录,只有一层目录和三个文件,当我们建立一个子目录并且添加文件,例如:
mkdir Inc
touch Inc/test.h Inc/test_bak.h
git add Inc/*
git commit -m "Subdirectory"这时,上图中的Tree除了三个文件:README、LICENSE、test.c之外还有一个Tree节点指向目录Inc,而该节点下辖另外两个blob节点代表文件:test.h和test_bak.h。假设我们进行了三次提交,那么Commit之间的数据组织关系如下所示:
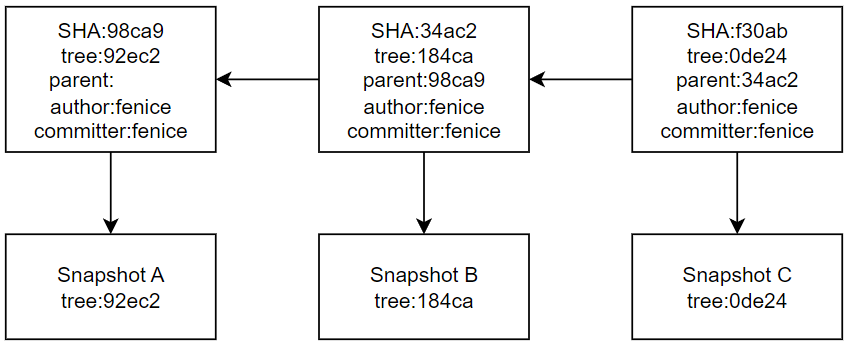
如上图所示,首次Commit是没有Parent信息的,这代表着这个commit是仓库的第一次提交,而后每一次提交,例如快照B基于A变更而来,那么第二次commit的Parent就指向第一次commit的校验值,以此类推可以得到ABC三个版本的迭代关系。根据这种数据组织方式,我们将这种具有清晰迭代关系的一系列提交和快照称之为一个分支(Branch)。分支本身也是一个指针,指向这一系列迭代中的最后一个提交:
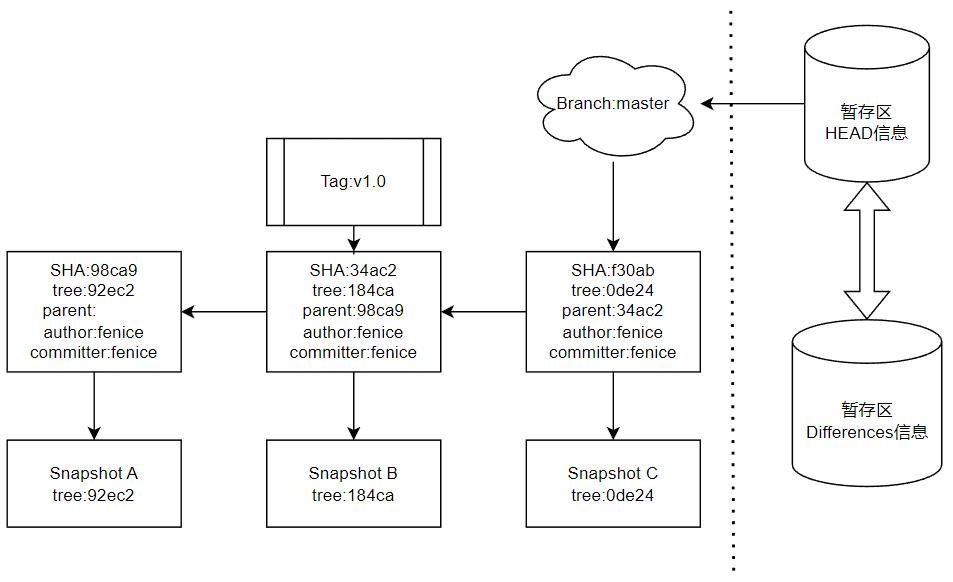
首先需要说明的是,Git的默认分支,也就是主分支命名为master,虽然从2020年开始GitHub和GitLab已经将这个默认分支命名为main,但是Git本身还是叫它master。当我们进行了第一次提交,master指针指向这次提交[98ca9],当我们在Snapshot A的基础上进行了变更有了第二次提交,master指针指向了对应快照版本Snapshot B的第二次提交[34ac2]。这里需要指出,前文提到的标签(Tag)本质上也是一个指针,例如我们在B快照建立一个名为”v1.0″的Tag,事实上就是将这个Tag指向了第二次提交。随着我们进行了C快照的提交master会按照迭代关系自动指向第三次提交[f30ab],但是Tag不会自动迭代前进。那么,假设一个工程中具有很多个分支(这是十分常见的情况)我们如何标记我们当前工作区和暂存区究竟属于哪个分支的迭代关系呢?我们在暂存区(Stage)中也设有一个指针HEAD,指向了我们“当前使用的分支”,根据HEAD信息,我们进行提交时会自动使用该分支的迭代关系,将新的Commit挂载到该分支下。
4.1.2 如何新建一个分支
#查看最后一次commit所属的分支
git log -1
#log输出信息如下:
#commit 4b0105c646479e821d9037cda62efa3a82939ca4 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code and Newfile我们使用log指令来查看一下我们前文一直使用的样板工程的HEAD信息,我们可以看到在输出中明确记录了HEAD指向了master分支(HEAD -> master)。接下来我们讨论如何新建一个分支:首先需要明确的是,在Git中除了master以外,其他的分支不能够“无中生有”。也就是,Parent为空的情况只可能出现在master分支的第一次提交中,其他的分支必须从已经存在的commit新建。假设我们从当前commit新建一个分支命名为test,他看起来大概是这样的:
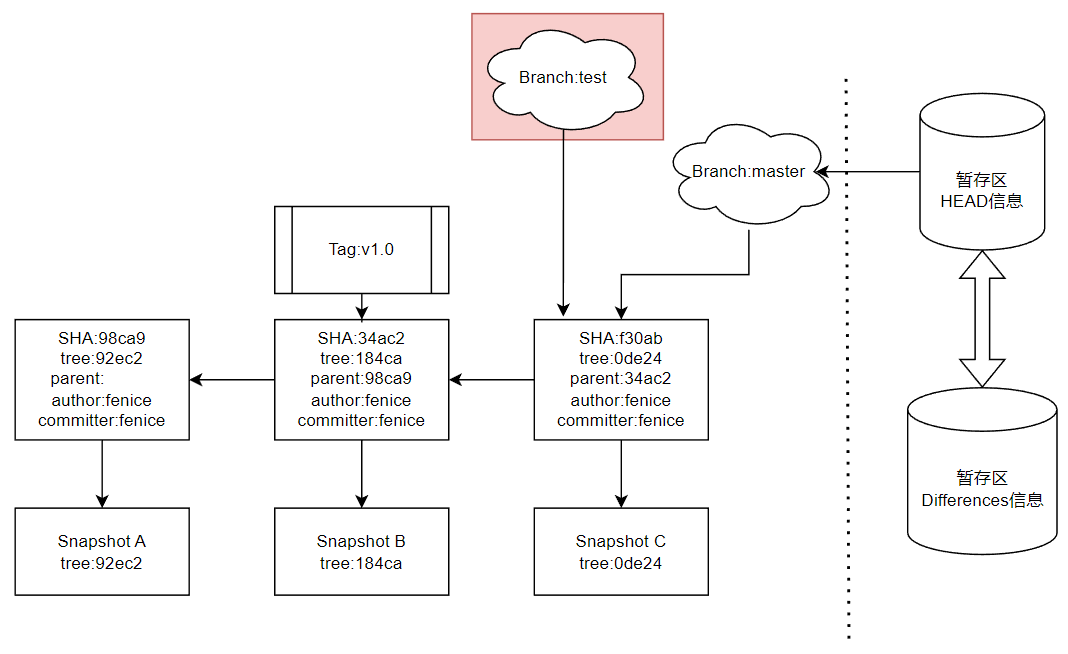
本质上,我们是新建了一个名为test的分支指针,指向了当前Git仓库中最后一次,或者准确的说,当前HEAD指向的commit。例如我们在样板工程中新建一个test分支并且使用log查看:
git branch test
git log -1
#log输出结果如下:
#commit 4b0105c646479e821d9037cda62efa3a82939ca4 (HEAD -> master, test)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code and Newfile4.1.3 如何切换工作分支
在上文的log输出中,我们可以看到最后一次提交中有两个分支指向它:master和test,但是值得一提的是如果我们关注HEAD,我们会发现HEAD仍然指向master,也就是说我们此时如果做出一些改变并且提交到Git仓库,那么这次新的提交将会仍然挂载到master,而test分支并不会改变,示意图如下:
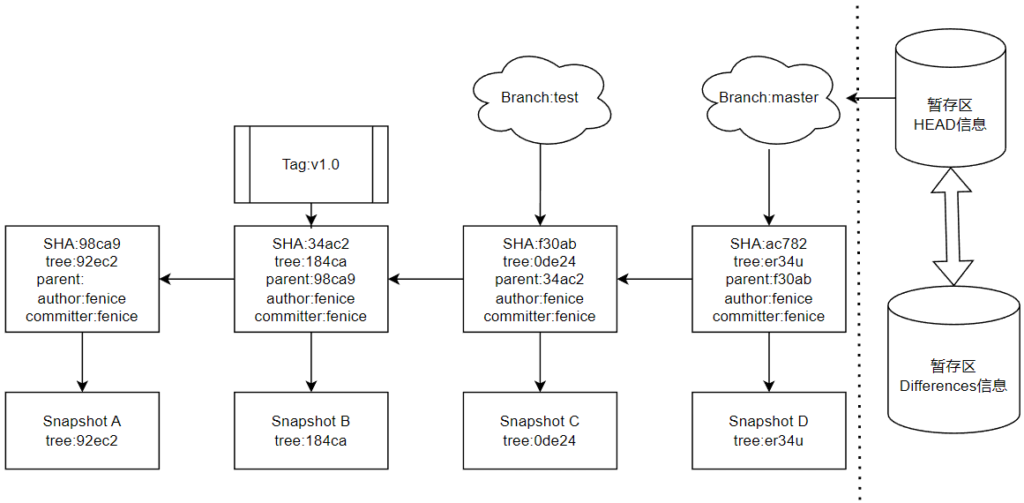
可以看到如果我们提交了Snapshot D那么这个快照会附加迭代到master分支中,而test分支将继续停留在快照版本Snapshot C中。这种现象的原因就是因为HEAD指向了master,所以当我们执行commit命令时实际上快照版本和提交信息会迭代到HEAD指向的分支。那么切换工作分支本质上就是改变HEAD:
git checkout test
#输出信息为:
#Switched to branch 'test'
git log -1
#log输出信息:
#commit 4b0105c646479e821d9037cda62efa3a82939ca4 (HEAD -> test, master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code and Newfile我们可以看到HEAD目前已经指向了test分支,如果我们现在做出改变并且提交,这个提交就会被迭代分配到test分支,我们不妨做出如下试验:
#向分支test中提交一个新文件new.c
touch new.c
git add new.c
git commit -m "commit to branch test"
git log -2
#log输出如下所示:
#commit a308358481b16cbc7a15223afee54df7f9ff7bdb (HEAD -> test)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Mon Apr 17 00:47:12 2023 +0800
#
# commit to branch test
#
#commit 4b0105c646479e821d9037cda62efa3a82939ca4 (master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Wed Apr 12 03:06:40 2023 +0800
#
# Rename Code and Newfile可以看到,在log输出的过去两次提交中,我们发现master分支仍然停留在倒数第二次提交,而test分支已经来到了新的最后一次提交的版本中。如果我们切换到master进行提交会发生什么,试验如下:
#向分支master中提交一个新文件old.c
git checkout master
touch old.c
git add old.c
git commit -m "commit to branch master"此时执行log命令并不会输出test分支的内容,为了工程人员的管理方便,一般git log指令只会输出和当前分支有关的提交,而上一次对test的提交显然不会加入到master的输出范围内,我们需要使用参数–all才能够看到所有的提交。加入–decorate和–graph选项可以图形化的看到分支的变更,例如:
git log -2 --all
#log输出如下:
#commit 0be698600f56f76dac242d6769def34fdd4845e9 (HEAD -> master)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Mon Apr 17 00:48:06 2023 +0800
#
# commit to branch master
#
#commit a308358481b16cbc7a15223afee54df7f9ff7bdb (test)
#Author: Fenice Liu <feniceliu@fenice.website>
#Date: Mon Apr 17 00:47:12 2023 +0800
#
# commit to branch test
git log --decorate --graph --all --oneline
#log输出如下所示:
3* 0be6986 (HEAD -> master) commit to branch master
3| * a308358 (test) commit to branch test
#|/
#* 4b0105c Rename Code and Newfile
#* 0658006 Delete README
#* a633bb9 Test .gitignore
#* 7f9867f Add README and modified LICENSE
#* a07262f Initialize Project当然,我们亦可以在checkout指令中添加选项-b达成在新建一个分支的同时将工作区切换到新建分支。在Git版本高于2.23的命令语法中,我们还可以使用switch指令和-c/–create选项达成这一目的:
#新建分支new并且切换到该分支
git checkout -b new
#使用switch命令切换分支
git switch master
#使用switch -c/--create新建分支new并且切换
git switch -c new
git switch --create new4.2 基本分支(Branching)管理与合并(Merging)
分支这一概念自从加入到Git中就受到广大开发者的喜爱,而在日常的工作流程中,创建分支、管理分支和合并分支是最常见的操作,在一个工程的开发流程中,我们大概需要进行如下几步:
- 首先在Git服务端(一般来说是个Web,例如GitHub、GitLab或者什么私有部署的Web管理)上进行一些基础的部署,例如创建仓库,写入LICENSE和README等等
- 针对于开发者当前需要做的事务创建一个分支或者从若干分支合并到一个新的分支并签出
- 随后在第二步创造的分支上进行开发工作
一个更加常见的场景(无论你是卓越的全栈开发大神还是被迫在地铁上加班的社畜)就是当你项目的发行版本出现了一些BUG,而且是致命性的BUG,你通常需要进行快速修复(hotfix):
- 切换到你的产品分支
- 从产品分支的BUG快照版本创建一个全新hotfix分支
- 在hotfix分支上进行修复和测试,随后将补丁程序作为一个commit合并到发行版本分支
- 处理完毕BUG后继续正常的开发工作
4.2.1 分支工作流(Workflow)实例
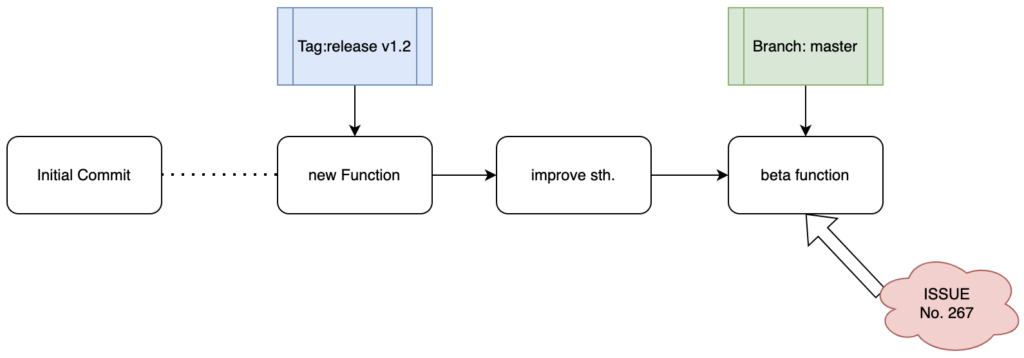
现在考虑这样一个场景,你作为某知名项目的开发人员,有一天你的邮箱接到了一个GitHub发来的邮件通知你后台有一条Issue亟待解决,系统将这个issue编号为267,那么你需要:
#从当前master的commit创建一个分支并且签出到该分支
git checkout -b issue267
#做出一些改变后,提交issue的修复方案
git commit -m "Fix several bugs"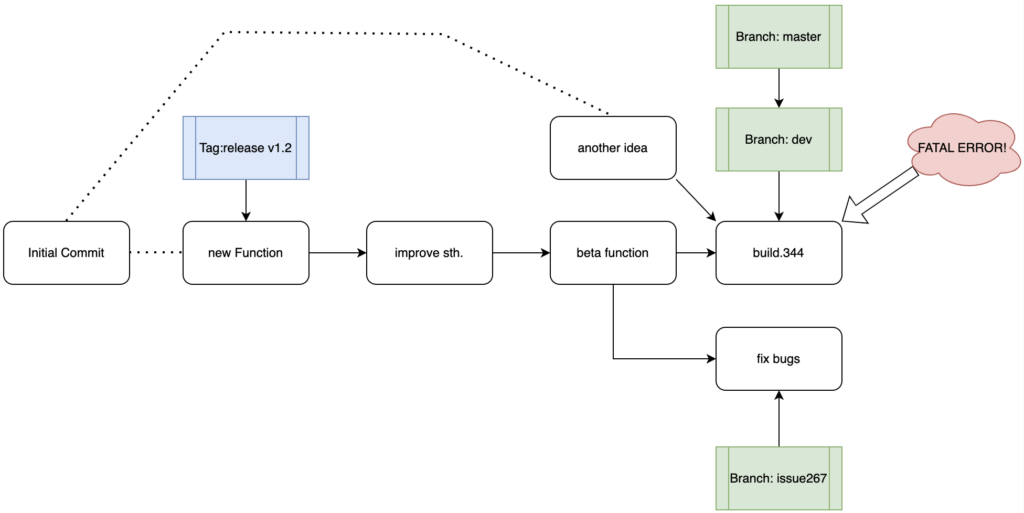
当你在对着267号ISSUE大干特干修复了一些BUG并且进行了一次commit时,你的猪队友们也没有闲着摸鱼,负责dev分支的同事们提交了一个名为“another idea”的commit。你们的项目负责人看到了这个提交并且认为你们可以进行一次版本升级,他合并了这两个分支……然后BOOM!发生了致命错误,你作为劳模被选中立即修复这个BUG并且保证master在此期间仍然没有变动(不要问我为什不直接回滚,这就是个例子),那么你应该:
#首先从当前的master建立一个hotfix分支
git checkout master
git checkout -b hotfix
#修复hotfix分支上的bug,打补丁
git commit -m "fatal error fixed"
#将hotfix分支合并到master主分支
git checkout master
git merge hotfix
#新建一个Tag作为新版本
git -a v1.3 -m "new version with wonderful idea"
#删除hotfix分支
git branch -d hotfix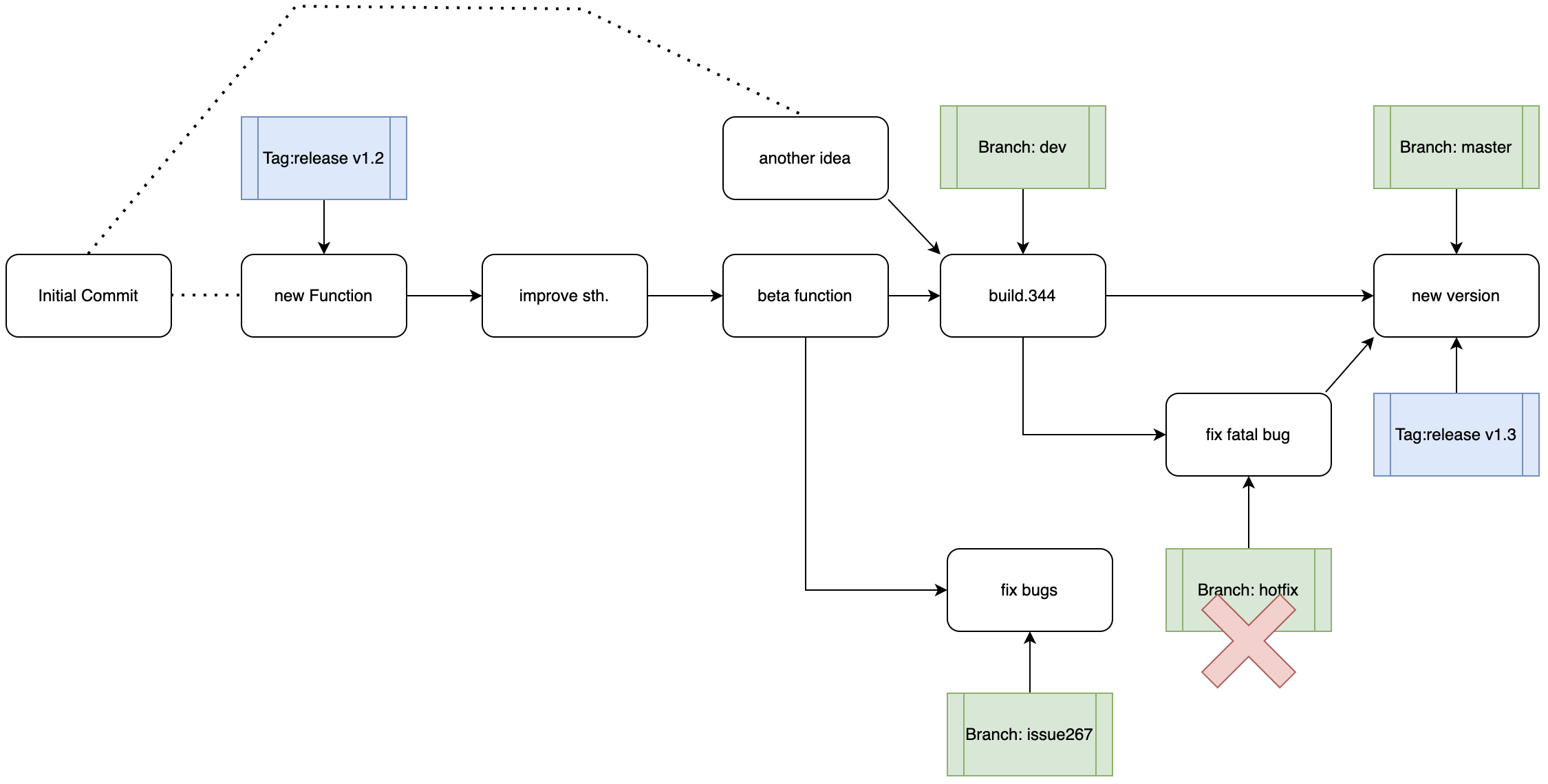
4.2.2 分支合并(Merge)与冲突(Conflict)管理
在上一小节的例子中,我们可以看到我们使用了一个提到但是从未详细分析过的指令:合并(Merge)。这其实很好理解,从逻辑上来讲,如果分支只能够不断的新建和没头没尾的删除,那么分支这个重要功能其实不必作为Git的核心卖点,因为在这种应用条件下,分支其实只能够做测试和验证目的使用。当我们将一个项目分为各种不同的目的并行开发后,我们总要“殊途同归”、”海纳百川“的将所有的新功能和所有的补丁融合在一起创造出新的发行版本,这时候我们就会用到合并这个功能。
我们在之前的例子中,看到了将hotfix分支合并到master这个动作,值得注意的是,我们在执行merge之前需要先checkout到master分支,这是因为合并时Git会将被合并分支迭代到到当前HEAD信息之中,所以我们需要首先将合并到的目标分支checkout。命令写为:
git merge <branch>
#branch 代表着被合并的分支的名称,该分支的branch指针信息将会同步到HEAD信息现在,我们来考虑一些略微复杂的情况,例如假设我们要将现在的issue267分支合并到master分支,这就会产生一些问题:hotfix分支当前的parent节点就是从master创建该分支的节点,也就是说这两个分支有共同的直接父节点,那么合并的本质就是将master指针迭代到hotfix指向的快照即可。但是当我们试图去合并issue267和master时我们会发现,他们没有共同的直接父节点,那么这个时候Git会做一个非常经典的模型:三路合并。所谓三路合并之中的前两路我们都好理解,也就是master和issue两个分支当前的快照,但是第三路是什么呢?事实上是他们的共同祖先节点,示意图如下:
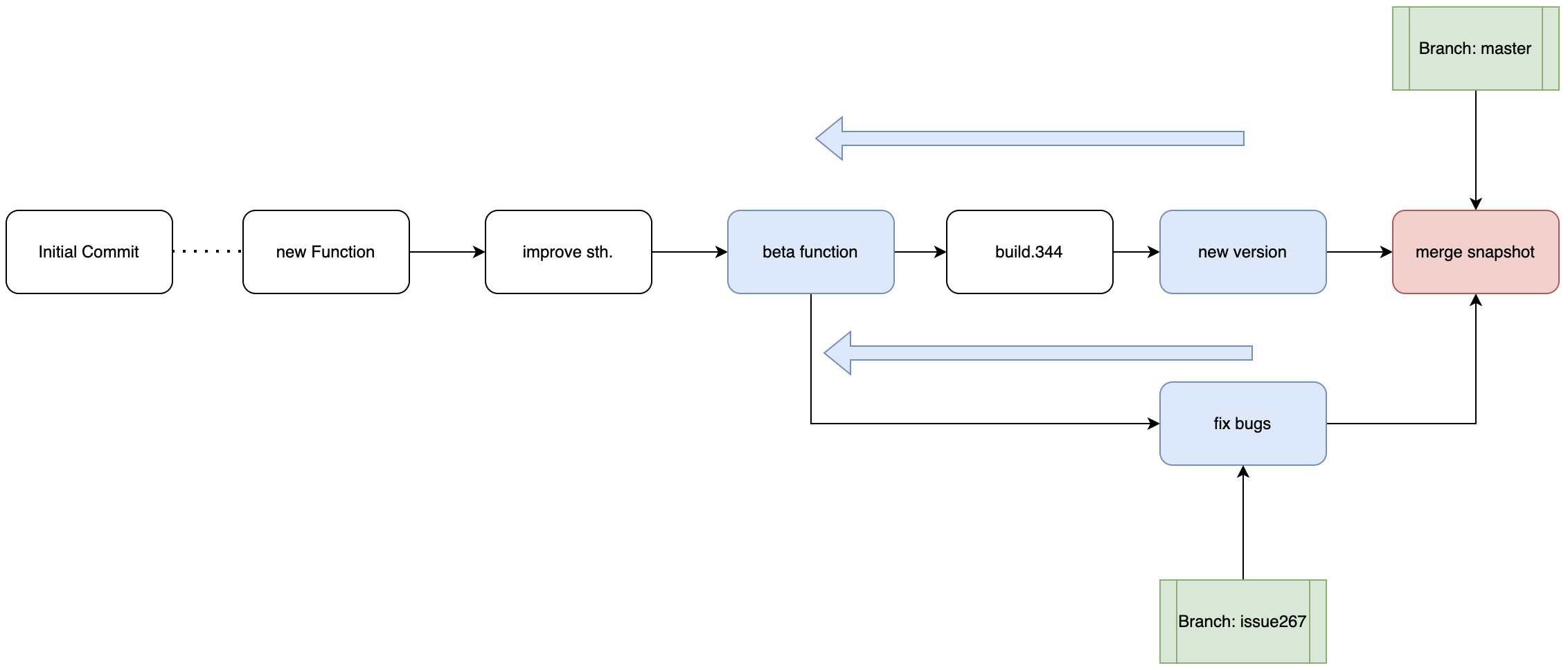
Git首先按照每个commit指针中父节点(parent)的信息不断向前迭代,直到找到二者最近的共同祖先commit节点也就是图中的beta function,然后以其为基础,融合两个分支的最新commit创造一个全新的快照,这也是三路合并模型和上文提到的简单合并模型最大的不同点,此时master指针迭代到最新的快照,但是另一个分支却并没有迭代到该节点(在三路模型中就能够看到“合并到分支”和“被合并分支”的区别)。但是以上例子中有很重要的一点被我们漏掉了:假设此时issue267分支和master分支同时对同一处代码进行了不同修改要怎么办?这就是合并过程中的合并冲突(merging conflicts)。回到我们之前一直使用的例子中,我们现在有test和master两个分支,我们不妨人为的构造一个合并冲突,也就是向两个分支下的文件test.c中各自写入不同的内容:
#在master中的test.c文件写入一个版本
git checkout master
echo "#include<stdio.h>
int main(){
printf("Hello World in branch master\n");
return 0;
}" >> test.c
git add test.c
git commit -m "make conflict in master"
#在test中的test.c文件写入另一个版本
git checkout test
echo "#include<stdio.h>
int main(){
printf("Hello World in branch test\n");
return 0;
}" >> test.c
git add test.c
git commit -m "make conflict in test"
git log --decorate --graph --all --oneline
#查看当前log信息如下
#* c5d54cd (HEAD -> test) make conflict in test
#* a308358 commit to branch test
#| * 4a60014 (master) make conflict in master
#| * 0be6986 commit to branch master
#|/
#* 4b0105c Rename Code and Newfile
#* 0658006 Delete README
#* a633bb9 Test .gitignore
#* 7f9867f Add README and modified LICENSE
#* a07262f Initialize Project从log输出信息中我们可以看到,从快照4b0105c开始,master和test两个分支开始产生变化,在各自下一次提交(4a60014、0b36986)之中各自添加了一个文件(这并不会引起冲突,同时保留两个文件即可)而后再下一次提交中,二者更改了test.c,产生了冲突,如果此时执行merge:
git checkout master
git merge test
#merge输出信息如下所示
#Auto-merging test.c
#CONFLICT (content): Merge conflict in test.c
#Automatic merge failed; fix conflicts and then commit the result.可以看到当我们执行merge命令时,Git默认进入了自动合并程序,而后git在合并到文件test.c时就注意到了二者不可调和的矛盾,于是将矛盾详细内容存入到暂存区,暂停合并程序并等待用户处理完毕。我们此时执行status命令查看冲突的详细信息:
git status
#status输出信息
#On branch master
#You have unmerged paths.
# (fix conflicts and run "git commit")
# (use "git merge --abort" to abort the merge)
#
#Changes to be committed:
# new file: new.c
#
#Unmerged paths:
# (use "git add <file>..." to mark resolution)
# both modified: test.c可以看到,Git已经在暂存区中确定了新文件new.c(来自于test分支新建的文件,可以看到两个不同的文件并未产生冲突)但是报错了二者同时修改的test.c。当然,在上面的status输出信息中我们可以发现如果我们要放弃产生冲突的合并,我们可以执行:
git merge --abortGit本身带有能够解决冲突或者说展示冲突的文本标记工具,我们只要查看当前工作区中产生冲突的文件本身,我们就能够看到冲突。如下所示,在”<<<<<<< master”和”>>>>>>> test”之间展示的是冲突的具体内容,“=========”是分隔符,分隔符上方是master之中冲突部分的具体内容,之下则是test分支之中冲突部分的具体内容。
cat test.c
#文件内容显示如下:
# #include<stdio.h>
# int main(){
# <<<<<<< HEAD
# printf("Hello World in branch master\n");
# =======
# printf("Hello World in branch test\n");
# >>>>>>> test
# return 0;
# }我们只要在文件中手动以文本编辑的方式书写一个结果即可,不必选择两个分支其中任何一个作为特定的结果。当然,我们也可以使用Git自带的图形化工具查看合并冲突,执行命令git mergetool即可。我们在这里选择如下处理:
#选择将文件中printf语句写为: printf("Hello World merged\n");
#将修改过的文件添加到暂存区
git add test.c
#输入commit指令完成合并
git commit
#这里没有写提交信息,如果直接输入这条指令会发现进入vim编辑器后,作为message的第一行已经被写为:
# Merge branch 'test'
git log --decorate --graph --all --oneline
#log输出内容
#* 9f21632 (HEAD -> master) Merge branch 'test'
#|\
#| * c5d54cd (test) make conflict in test
#| * a308358 commit to branch test
#* | 4a60014 make conflict in master
#* | 0be6986 commit to branch master
#|/
#* 4b0105c Rename Code and Newfile
#* 0658006 Delete README
#* a633bb9 Test .gitignore
#* 7f9867f Add README and modified LICENSE
#* a07262f Initialize Project4.2.3 其他基础分支管理命令
#查看当前分支,前面带*的是当前checkout的分支
git branch
#查看所有分支,包括远程分支
git branch --all
#查看当前所有已合并分支
git branch --merged
#查看当前所有未合并分支
git branch --no-merged
#查看未合并到指定分支的分支,以master为例子
git branch --no-merged master
#删除已存在分支<branch_name>代表需要删除的分支名称
git branch -d <branch_name>
#将分支<old_name>重命名为<new_name>
git branch --move <old_name> <new_name>以上命令全部都通俗易懂,只是在重命名内容中,需要注意的是,远程仓库的分支重命名并不能粗暴的这样运行,例如将远程远程的master分支重命名为main分支:
#首先在本地完成重命名
git branch --move master main
#将新分支名称推送到远程,例如远程仓库名称为origin
git push --set-upstream origin main
#此时远程仓库新旧分支名称对应的分支同时存在,需要删除旧的分支
git push origin --delete master4.3 远程分支管理
远程仓库中有一类数据,不涉及具体的快照或者工程文件本身,只代表着一种标记,有点类似于C++中的引用,本质上也就是一个指针,我们称之为远程引用信息(Remote References),包括远程仓库之中的分支信息、标签信息等。我们可以通过以下两种命令查看:
git ls-remote <remote_name>
git remote show <remote_name>
#<remote_name>指远程仓库的名称,例如origin4.3.1 远程仓库分支管理机制
Git对于远程仓库的管理和我们查看管理远程仓库的方法其实可以依托于一种更加有效的工具:远程跟踪分支(Remote Tracking Branches)。这些分支本质上也是引用标记,也就是某种程度上的指针,根据远程仓库的信息指向本地仓库的对应部分,并且用户不可以更改。当我们连接网络同步远程仓库时,Git将会自动的代替我们改变这些引用信息以确保这些引用信息精确的符合远程仓库中的真实情况。
我们使用<remote_name>/<branch_name>来代表指向远程仓库的分支引用标记,例如我们链接到了一个远程仓库origin,那么其中的master分支在本地需要写作:origin/master。但是这里需要特别强调的就是:远程仓库的分支引用只是“远程仓库在本地的投影”,例如:
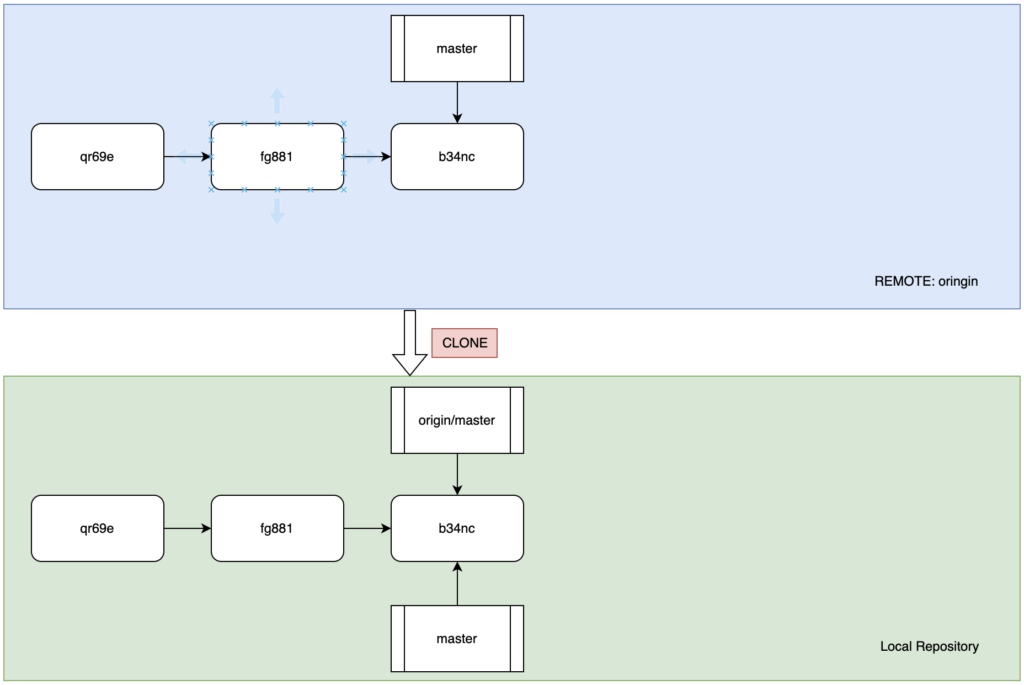
如图,蓝色部分代表名为origin的远程仓库,绿色部分代表本地仓库,本地仓库通过clone命令将远程仓库完全复刻到本地。如图所示,本地仓库的远程分支引用origin/master并不是master本身,而是和master一样的一个指针,只不过不可以通过用户的命令直接更改。假设远程仓库有其他人做了commit和push,本地的开发人员也进行了进一步的变更,但是没有过同步动作,如下所示:
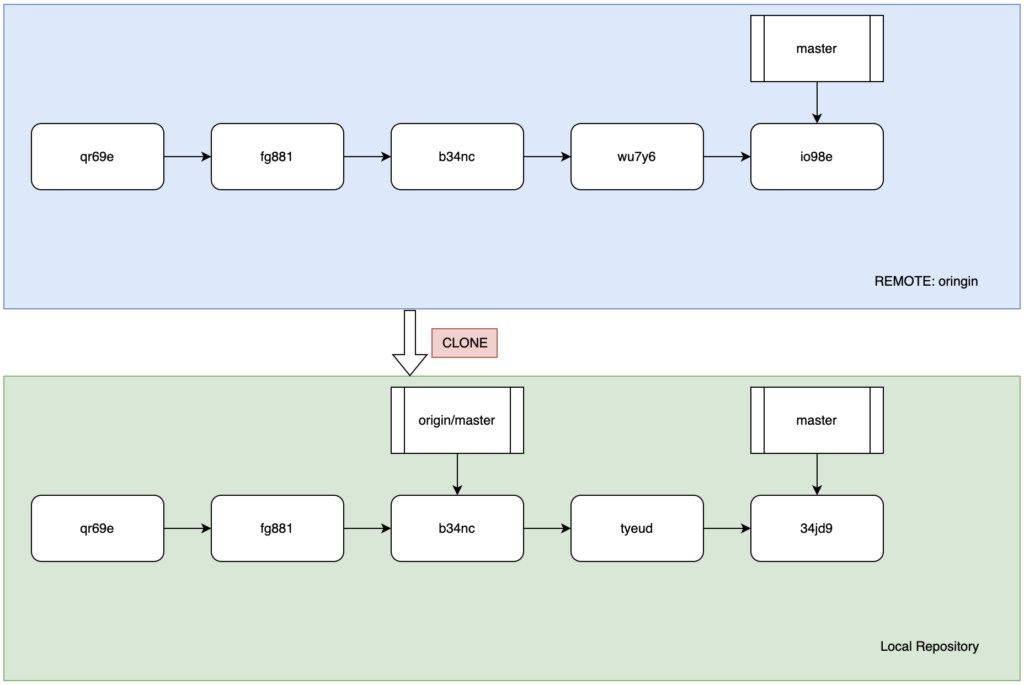
可以看到,本地和远程都做了两次更改进行了两次commit,同样的两个仓库中的master指针也都随着两次提交迭代到了最新的节点,但是由于没有同步远程仓库,所以本地的origin/master仍然停留在原地。为了解决这种不同步的状况,我们可以使用git fetch origin命令将远程仓库的引用同步到本地如下:
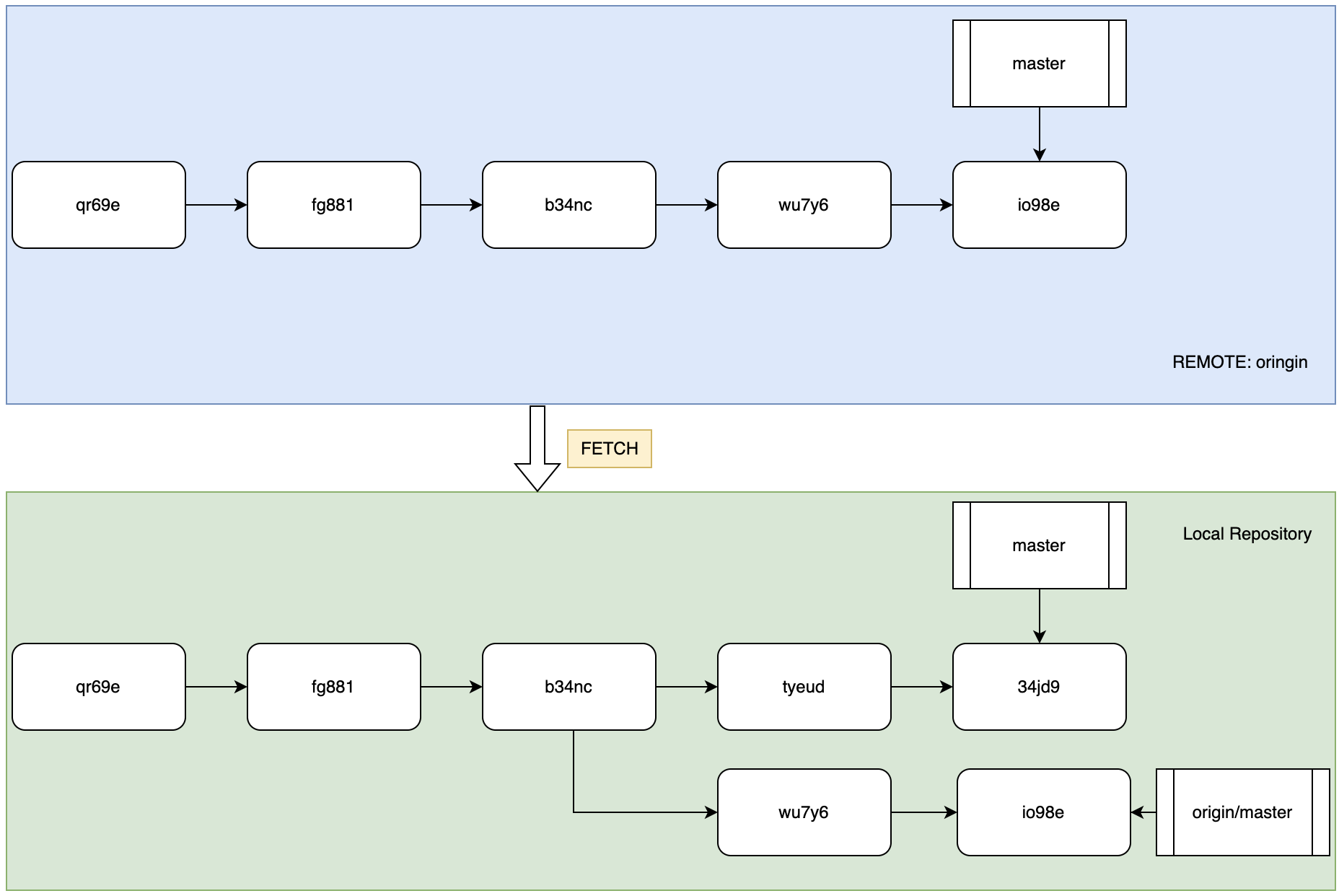
可以看到,fetch命令并不会直接改变本地仓库中的分支信息,改变的是本地仓库中的远程分支引用信息,也就是origin/master作为一个独立的像其他分支一样的分支被标记出来。根据上图不难想象多个远程仓库各个执行过fetch命令后的景象,此时就可以通过本地仓库的分支查看管理命令作用于这些本地引用。
4.3.2 远程分支管理之PUSH
首先要明确一点,Git是能够应对非线性工程开发结构的版本管理工具,我们大可以把本地的工作区和仓库内容“搞得一团糟”而并不同步给团队中的其他开发人员。但是我们总要将手头的工作保存到远程备份或者分享给其他队友,我们就需要将本地分支推送(PUSH)到我们具有写入权限的远程仓库。在前文的叙述中我们已经使用过push命令,如下所示:
#语法 git push <remote_name> <remote_branch>
#例如将当前分支master(本地)PUSH到origin仓库中的dev分支
git push origin dev上述命令只是一个最简化版本的PUSH指令,事实上它进行了很大程度的缺省。当我们使用PUSH命令时事实上完成了至少两个动作:首先将本地所有未同步的commit发送到服务端,而后将服务端的branch指针指向推送时本地branch指针指向的commit节点(为什么至少两个?这里只谈论主要的步骤,其他的例如将本地的远程分支引用进行同步更新当然也会进行)。简化版本的PUSH指令在对齐指针这一步事实上完成的是如下的命令:
git push origin refs/heads/master:refs/heads/serverfix
#完整命令格式为 git push <remote_name> <local_ref>:<remote_ref>
#一般省略refs/heads路径
#由于push的对象就是当前分支,故而也可以省略
#若将本地的hotfix推送到origin远程的backup分支
git push origin hotfix:backup值得一提的是,被推送的远程分支不一定要存在,也就是说假设在上面的例子中远程Git仓库中并没有一个叫做backup的分支,那么这一命令会在远程自动创建一个分支backup。当然,假设另一位开发者在他的本地仓库进行了fetch,backup分支并不会直接写入到他的仓库中,而是作为名为origin/backup的远程分支引用存在,当然他可以:
#将backup的内容合并到自己的本地工作分支
git merge origin/backup
#将backup签出到本地成为新分支
git checkout -b backup origin/backup4.3.3 远程分支管理之Track
前文提到的各种分支管理,尤其是远程分支管理中我们似乎没有建立“远程分支和本地分支的对应关系”这一概念,如果每次都要频繁的签出或者合并远程分支,真的算得上是新时代的顶级折磨。事实上在Git中有这样一个概念,每个本地分支都有一个数据条目叫做跟踪分支(tracking branch),指代的就是与该分支建立对应关系的远程分支,也叫做上行分支(upstream branch)。事实上,我们在签出时通过制定的命令行参数–track确保追踪关系的建立:
git checkout --track origin/hotfix
#该命令在本地新建一个hotfix分支并且将该分支签出到工作区
#--track命令一般而言是可以缺省的,例如以下两种场景:
git checkout origin/hotfix
#如果本地没有hotfix分支,那么这样的命令会自动创建hotfix分支并且建立追踪关系
git checkout -b serverfix origin/hotfix
#该命令将在本地建立分支serverfix并且追踪到远程服务器的hotfix分支建立追踪分支的意义在于,当我们fetch远程仓库时我们得到的只是各类指针信息,例如branch指针,tag指针,commit节点等,我们并没有将对应的快照数据存放到本地。假设建立了追踪关系,我们就可以通过极其简易的PULL命令将远程分支对应的数据拉取到本地分支。以上提到的都是新建分支并且建立本地与远程的追踪关系,假设我们有一个已经存在的分支我么可以通过参数-u或者–set-upstream-to来设置已经存在的分支的追踪分支关系,使用branch命令,也可以查看分支的追踪信息:
#语法 git branch -u <远程分支引用> 例如
git branch -u origin/hotfix
git branch --set-upstream-to origin/hotfix
#使用-vv选项可以查看分支的追踪信息,但是推荐首先同步所有远程仓库
git fetch --all
git branch -vv
#可能得到如下信息
# issue267 7e424c3 [origin/issue267: ahead 2] fix bugs
# master 1ae2a45 [origin/master] deploy index fix
#* serverfix f8674d9 [group/hotfix: ahead 3, behind 1] should do it
# test 5ea463a add a button在上方的branch信息中,可以看到test完全是一个本地分支,并没有建立任何远程仓库的追踪关系;前两个分支都对应到origin仓库的远程分支,serverfix分支是当前工作分支,对应到group仓库的远程分支。值得一提的是,我们会在输出信息中看到“ahead”和“behind”,这其实是简略的版本迭代信息。ahead代表本地分支有多少个commit没有PUSH到远程,behind代表远程有多少个commit没有PULL到本地。在Git的命令行中,Git为我们提供了一些快捷方式:我们可以使用@{u}或者@{upstream}来代替该分支的远程追踪分支本身,例如命令可以如下简写:
#假设现有分支追踪到origin/hotfix
git merge oringin/hotfix
#以上命令可以简写为
git merge @{u}
git merge @{upstream}4.3.4 远程分支管理之PULL与Delete
假设我们现在正在维护一个项目,我们的工作是负责审阅其他开发者的代码并且做出相关测试。我们的工作流程可以概括为两大部分:1.将远程仓库中的dev分支同步到本地并合并;2.将该分支新建签出为test分支开展工作,那么我们显然可以这样做:
git fetch origin
git checkout dev
git merge origin/dev
git checkout -b test1617 dev可以看到我们进行的第一个大步骤中可以分为两个小步骤,fetch和merge。前文提到fetch只是同步了指针信息,并没有改动本地工作区的内容;当我们执行merge命令时才会将远程内容合并到本地。现在我们可以通过我们前文十数次提到的PULL命令简化这一流程:假设当前分支具有upstream的远程分支,那么执行PULL指令时,会首先fetch对应的远程仓库,而后进行merge。那么命令简化为:
git pull oringin/dev
git checkout -b test1617 dev假设我们在本地删除了分支build289,Git在远程并不会进行这一操作,而且因为我们直接删除了这个分支我们也没有办法使用前文提到的常规的PUSH命令完成,我们只需要使用–delte参数即可。然而我们也不必太过担心错误的删除分支,因为这个命令只是删除掉了Git仓库之中的指针信息,真正的分支文件直到Git服务器进行垃圾回收(Garbage Collection)才会彻底删除,在此之前我们都可以恢复。
git push origin --delete build2894.4 分支管理中的变基(Rebasing)
在Git管理中,将不同分支的内容集成到同一分支中有两种主要方式,合并(Merge)和变基(Rebase),我们之前的内容主要讲述了分支管理中合并的方式。在这一部分中我们详细讨论变基的定义、工作方式、常见情况以及错误处理方式。
4.4.1 变基(Rebase)的基础工作方法
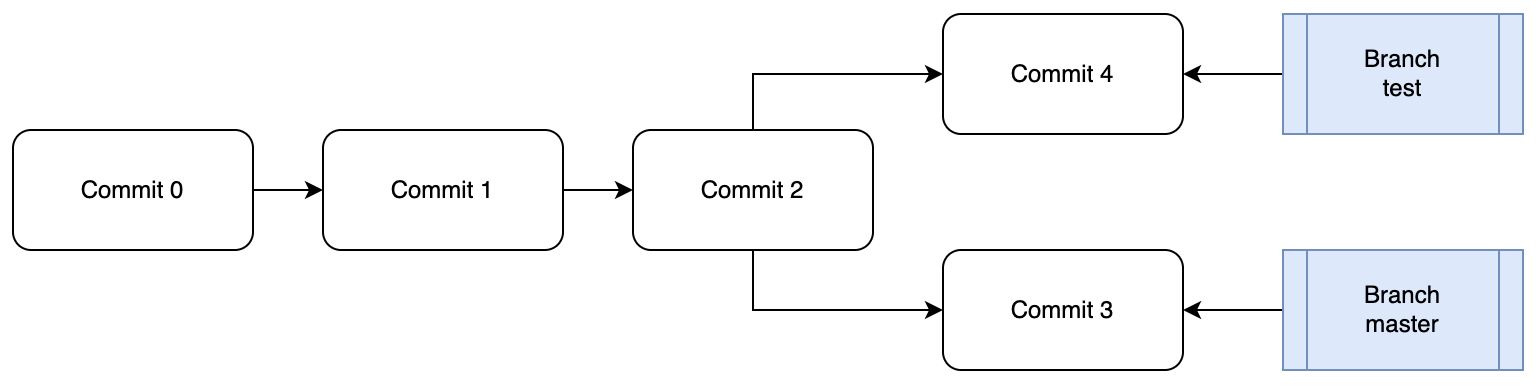
如上图所示,在本地Git仓库中,主分支是master,在Commit 2中创建了test分支,随后二者各进行了一次提交,如果此时需要将分支test合并到分支master,那么在master分支下使用merge命令即可完成。分支结构拓扑图如下所示:
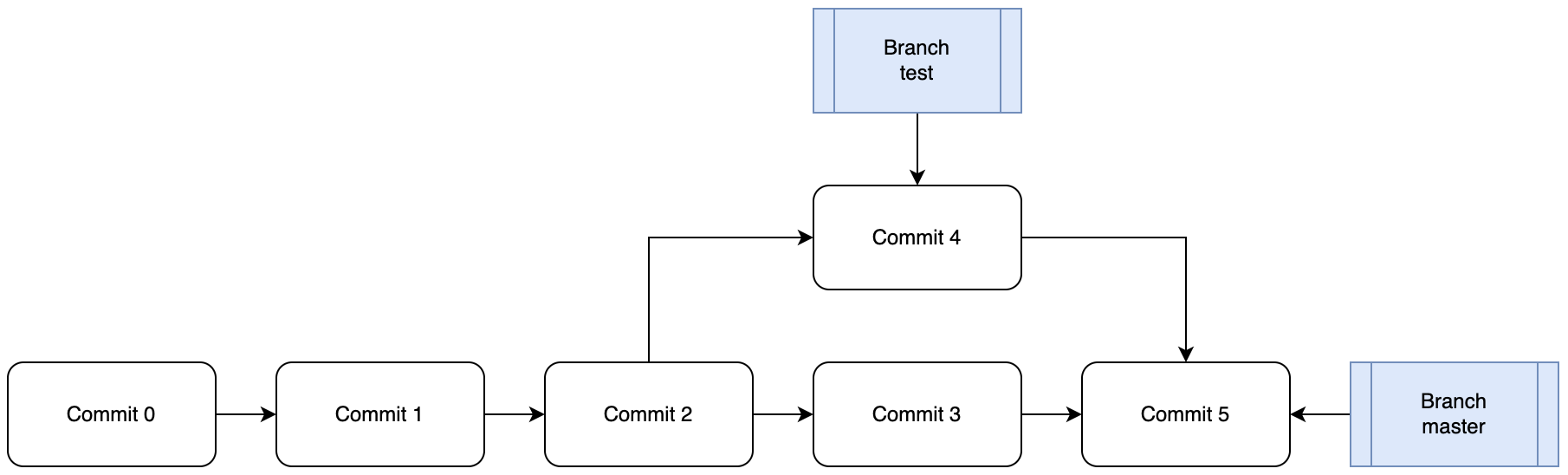
那么我们现在来聚焦于变基(Rebase)本身,首先要明确“基(Base)”是什么。我们都知道,Git每一次快照并不存储整个工程文件系统,而是存储相对于父节点的补丁(Patch)信息,那么“父节点(Parent Commit)”就是本次提交的”基(Base)“。在传统合并(Merge)中,Commit 5节点通过节点3作为Base,融入来自于节点4的Patch信息合成了节点5。那么有没有可能比较Commit4和Commit3两个节点,在节点3的基础上写入一些补丁信息完成合并呢?在前文讲述的合并流程中,我们曾经提到“三路处理”方案,那么我们是否可以认为,节点4与节点3拥有共同祖先节点Commit 2,将节点4以节点2为“基(Base)”剥离出补丁信息,挂载到节点Commit 3后形成新的四号节点。如下所示:
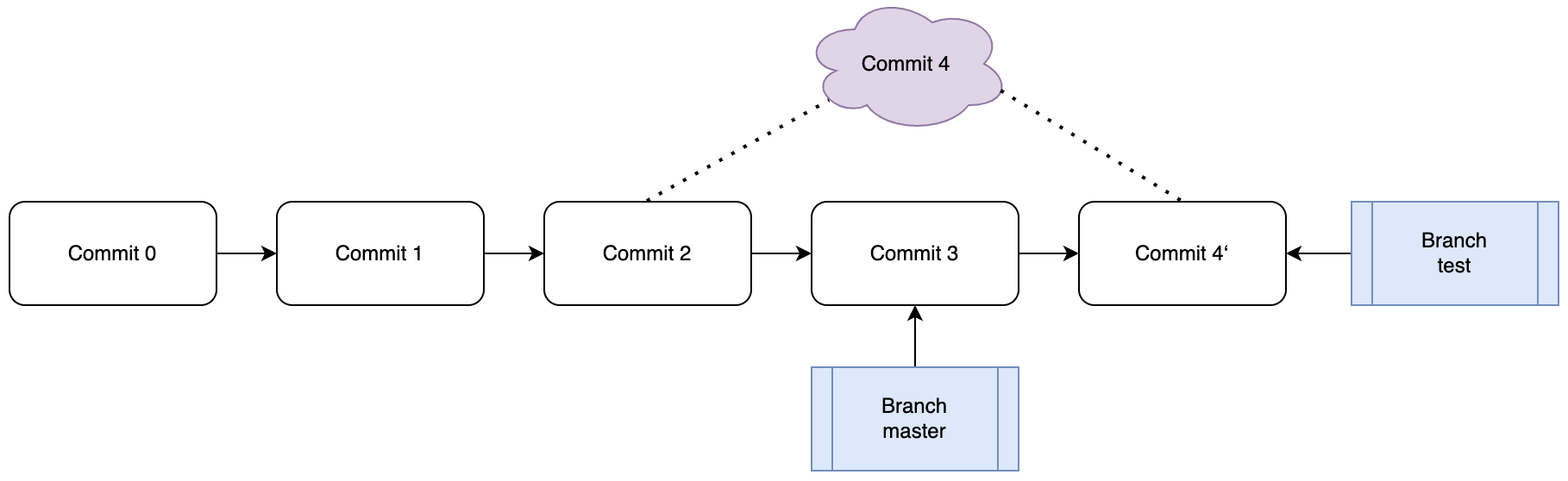
观察上图可知何谓“变基(Rebase)”,我们将Commit4的“历史沿革信息”从“C0->C1->C2+Patch(2->4)”变更为”C0->C1->C2->C3+Patch(3->4′)”,也就是改变了基础信息。使用rebase命令即可完成变基,可以看到在分支图中,master仍然停留在Commit 3节点,此时使用merge将master指针指向节点4‘即可,如下:
#首先签出到test分支,因为需要rebase的是test分支
git checkout test
#test变基后的目标分支是master,因此rebase后介入master
git rebase master
#此时git分支图如上所示,将master更新到迭代最新节点如下命令
git checkout master
git merge test此时对于master分支来说,无论是分支停留的最终节点还是节点的具体工程文件内容都和单纯merge没有区别。但是如果我们检验rebase过的分支历史我们就会发现整个test和master两个分支的历史记录是完全线性迭代的,看起来就像是所有的变更序列迭代,看不到曾经出现过分支的并行开发记录。变基这一操作通常用来“收拾自己的烂摊子”,例如我们在本地Git仓库进行了繁重且杂乱的开发工作,但是最后提交到远程仓库中的代码我们希望是一个拥有良好工程结构和迭代序列的版本,那么我们就可以变基后提交推送到远程仓库以清理本地开发的杂乱现场。
4.4.2 多分支的变基(Rebase)方式
现在考虑如下一个开发场景,我们在开发一个APP,主分支名为master,从提交C2开始,为了更好的完成工作我们额外划分出用于编写核心逻辑的Core分支,在Core分支进行了提交C3和C4,主分支进行另外两次提交C5和C6,随后从Core分支划分出专精于UI设计的分支UI,并且进行了提交C7和C9,主分支进行了提交C8,逻辑拓扑图如下所示:
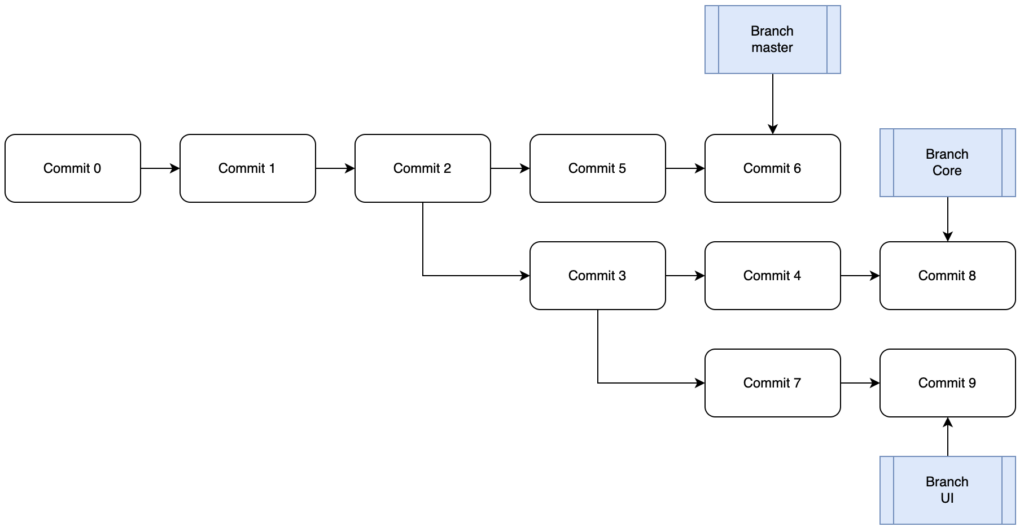
假设现在UI分支已经完成阶段性目标,需要将UI分支合并到主分支当中去,但是我们不想保留复杂的工程结构,因此需要Rebase。显然UI和master的共同祖先节点是C2,如果直接进行变基将UIrebase到主分支当中去,那么路径:C2->C3->C7->C9就会变为:C2->C5->C6->C3′->C7′->C9′。看起来问题不大,但是我们仍旧要保留Core分支继续开发测试,这样将来Rebase该分支时就在C3节点的处理上会出现重复的Patch信息。所以我们其实需要仅仅将C7和C9节点变基。于是我们使用–onto选项:
git rebase --onto master Core UI
#以上命令意位将UI分支“在Core的基础上”rebase到master分支
#语法 git rebase --onto <target_branch> <baseon_branch> <based_branch>
#target_branch 代表rebase到的分支
#baseon_branch 代表在xxx基础上的分支
#based_branch 代表需要rebase的认知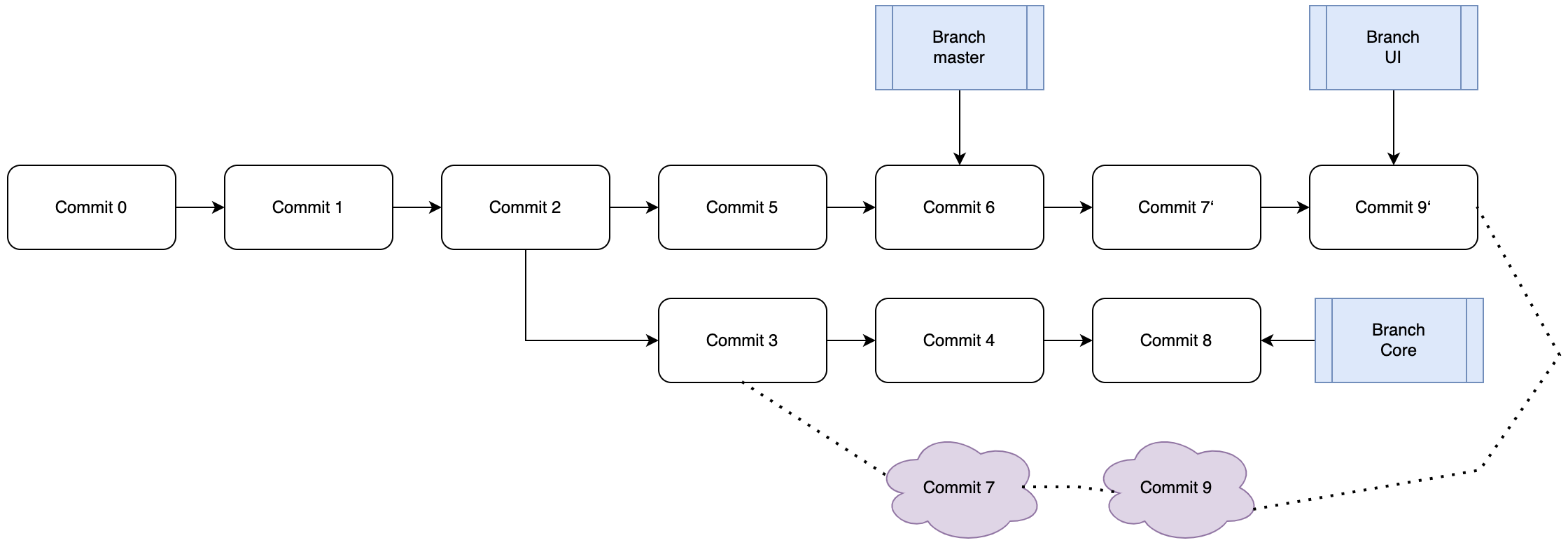
如上所示,可以看到达成了我们想要的目的,这时候继续Core的测试工作,测试完毕后将Core分支合并到主分支即可,而后merge掉两个分支,删除两个分支即可,如下所示:
git checkout master
git merge UI
git rebase master Core
git merge Core
git branch -d UI
git branch -d Core4.4.3 变基(Rebase)的危险情况和处理方法
Git变基是存在一定风险的,作为一个遵纪守法克己奉公的开发者,永远!永远!永远!不要将本地的变基结构推送到别人正在使用的分支!!!假设另外的开发者是基于某个分支的现有历史作为base进行开发工作的,那么贸然的rebase就会导致该开发者在merge远程变更时完全搞乱自己的工程结构。例如如下的分支拓扑图展示的工程:
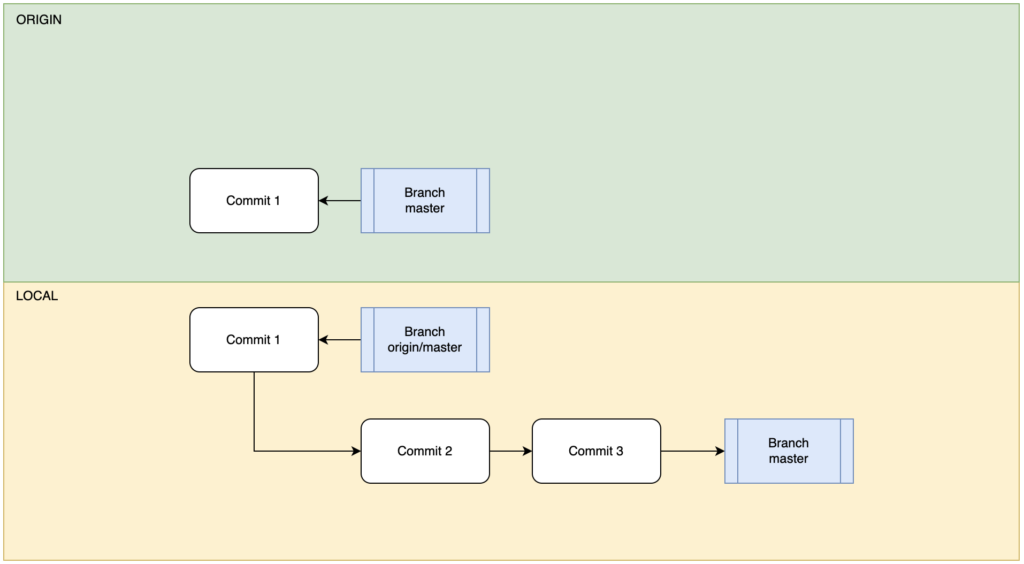
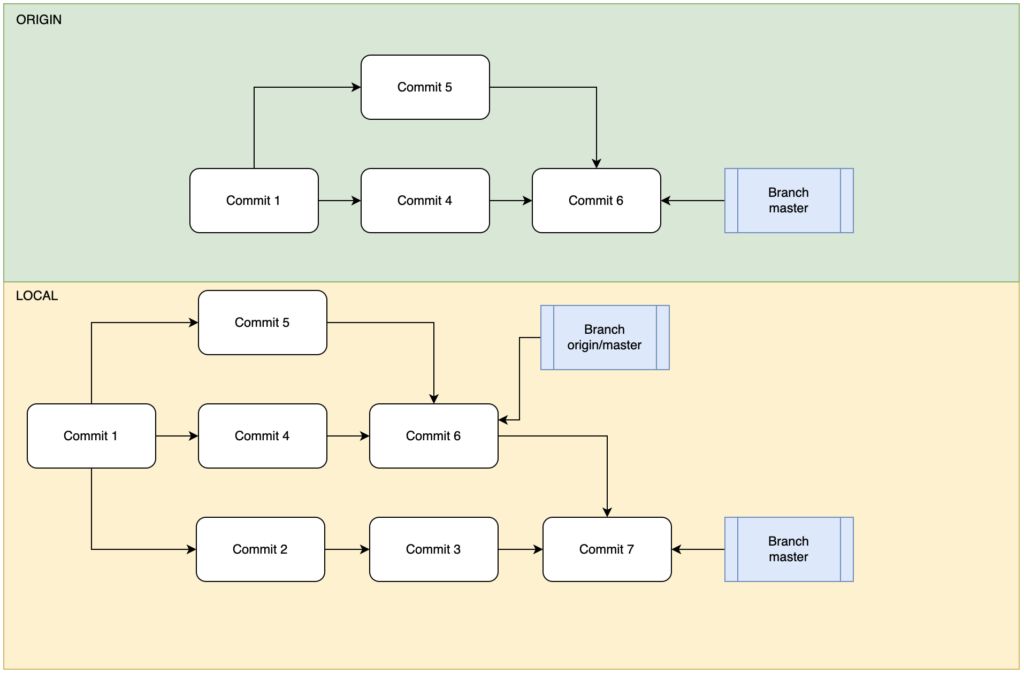
一开始在远程仓库中master只有一个提交C1,同步到本地后本地写入了提交节点C2和C3。其他开发者对云端仓库做了修改:创建了不知名分支并且提交了C5,对master提交了C4,而后将二者合并(Merge)到主分支C6节点。本地仓库同步云端后将C6节点的origin/master合并到本地master的C3构成了C7。这时候有一人间之屑使用了push –force命令rebase了云端的master,如下所示:
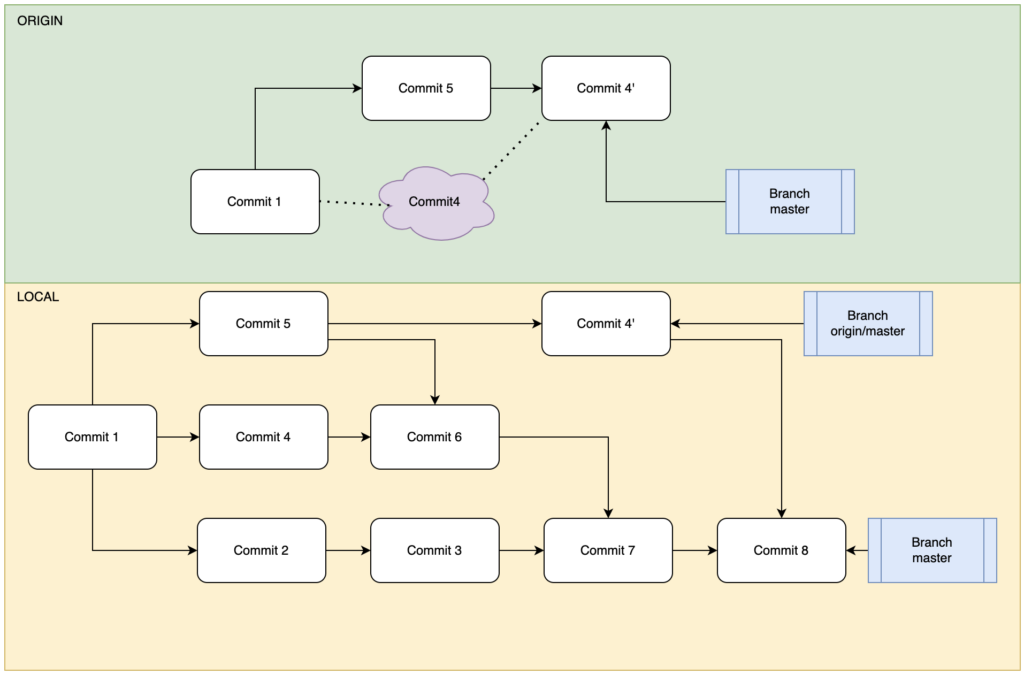
可以看到,云端仓库的rebase将master变基到了不知名分支,构成了历史记录C1->C5->C4′,而本地仓库fetch远程仓库时得到了该历史记录,但是这条历史记录从技术上和逻辑上都不会覆盖本地已有的远程引用记录C1->C4->C6和C1->C5->C6。这就构成了尴尬的景象,当我们fetch远程记录时发现master分支确有改变,需要进行合并(Merge),于是我们将C4’节点与C7节点合并得到C8节点。虽然从工程文件的内容上讲C7和C8几乎不会发生变动,但是这个行为确确实实破坏了本地的工程迭代结构。
那么假设说我们作为一个克己奉公遵纪守法的开发人员不知为何阴德有失,开发团队中出了一个逆天的鬼才私自rebase了“热线分支”。这个时候我们只能用魔法打败魔法,也就是在pull远程分支时rebase合并。我们知道合并有两种方式,merge和rebase,我们平常通常使用merge去合并分支,这时我们需要使用变基rebase合并分支。使用如下命令,达成如下图效果:
git pull --rebase
#如果要设置每次pull总使用rebase进行合并,可以使用如下配置
git config --global pull.rebase true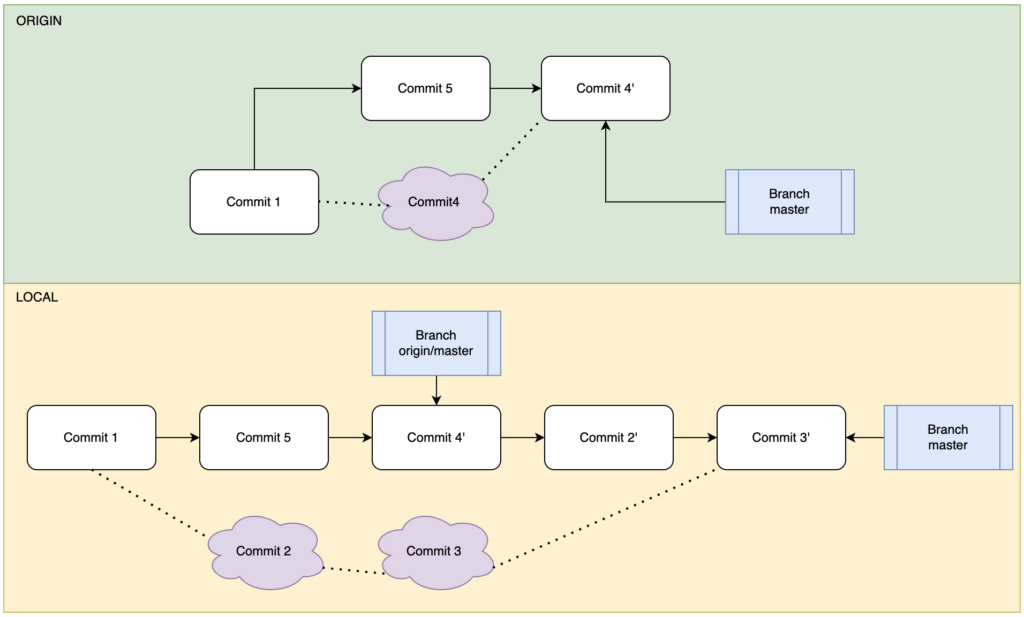
可以看到,由于将master变基rebase到origin/master,可以看到双方的共同历史记录至少从C1节点开始迭代,那么将之后的差异C2和C3两个节点rebase为C2‘和C3’挂载到C4‘节点之后,这样我们就重新拥有了整洁的工程迭代结构,从工程结构中剔除了“无必要、不健康”的节点。
4.4.4 关于变基Rebase和合并Merge的一些讨论
经过了上述的叙述,我们厘清了Git中最可能导致混淆的两个概念rebase和merge,这两种方式可以说是各有千秋,那么究竟孰优孰劣呢?有一个较为有趣的观点是,Git仓库记录的是“工程开发期间究竟发生了些什么”,主打的就是一个真实。从这个角度来讲,任何的rebase都是对现有记录的篡改和毁坏,显然是不好的是有悖于Git精神的。但是从另一个方面来说,开发工程就像土木行业修建建筑桥梁一样。我们当然可以用一组延时摄影或者干脆一部纪录片来描述某个宏伟建筑的产生,但是这并不意味着我们要把工人宿舍里的口角、饭后餐桌上的酒精、时不时不按规矩佩戴的安全帽也给记录下来。从这个角度来说,我们只需要保证工程主体的记录是真实且良好的就可以,一些鸡零狗碎的细节和曲折过程我们大可以不在意,这样来讲rebase简直是神器,而merge就会显得食古不化了。
作为我个人的建议,我们应当均衡二者,即能够做到反应工程开发的真实过程,又能隐藏起杂乱的施工现场和一些低级错误。个人习惯是,仅仅在本地的“施工现场”使用rebase,以确保最后提交到远程仓库的代码和工程迭代版本都是干净利落的结果;但是在远程仓库中非必要不应当使用rebase功能,应当尽可能的保证工程开发的完整性和真实性。

